

[AI新功能] 在Power BI 中使用 Copilot 提高 DAX 撰寫效率
本文章翻譯及摘要自 – 使用 Copilot 深入瞭解 DAX 查詢檢視 |Microsoft Power BI 博客 |Microsoft Power BI
使用 Copilot 編寫和解釋 DAX 查詢,提高 DAX 查詢檢視的工作效率。現在,通過備受期待的 Copilot 在 DAX 查詢檢視中編寫和解釋 DAX 查詢的公共預覽版,使用 DAX 查詢變得更加容易!
讓我們看看 Copilot 如何提供説明。
- 在 DAX 查詢中鍵入您想要的內容,Copilot 可以為您編寫。例如,僅按國家/地區顯示銷售額,甚至按特定列(例如產品)顯示所有度量值。系統會自動添加註釋,以解釋生成的DAX查詢的每個部分,並註明它是在使用者提示下使用 Copilot 生成的。
- 使用 Copilot 調整現有 DAX 查詢。添加其他按列分組,或以其他方式調整已寫入的 DAX 查詢。這種方法的好處是,您將看到 Copilot 使用內聯差異編輯器所做的所有更改,因此您可以確切地知道添加、刪除或更新了哪些內容。
- 使用 Copilot 創建新度量。DAX 查詢包括用於定義度量值的語法,在 DAX 查詢中,可以在不修改語義模型的情況下運行此度量值。因此,您可以創建度量值並試用它們。最後,在 DAX 查詢檢視中,如果要通過添加 DAX 查詢中的度量值來修改語義模型,則可以使用 CodeLens 來“更新模型”。
- 在使用 Copilot 的 DAX 查詢檢視中瞭解有關 DAX 函數或主題的詳細資訊。這個解釋將嘗試用你的語義模型給你一個例子:留在你工作的地方的上下文中。您不再需要使用其他模型來查找搜尋引擎的答案!
- 解釋已使用 Copilot 編寫的 DAX 查詢。讓 Copilot 逐步解釋您正在查看的 DAX 查詢中發生的情況。您需要的地方就是您自己的幫手!
讓我們看看它的實際效果。
若要繼續操作,請使用 https://learn.microsoft.com/power-bi/create-reports/sample-regional-sales 上提供的 Power BI 區域銷售範例。下載 PBIX 後,我做的第一件事是刪除「篩選器」窗格中的相對月份篩選器,以查看報告中的數據。
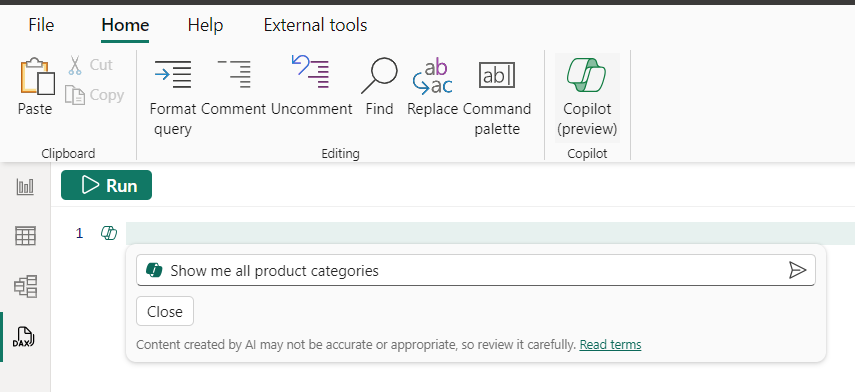
在 DAX 查詢中鍵入您要的內容,Copilot 可以為您編寫。 在這裡,我想稍微探索一下產品類別,所以我將要求通過“顯示所有產品類別”來查看它們。
- 轉到 Power BI Desktop 中的 DAX 查詢檢視
- 調用 Copilot:CTRL + I,按兩下功能區中的 Copilot 按鈕或行號旁邊的 Copilot 按鈕。
- 輸入「顯示所有產品類別
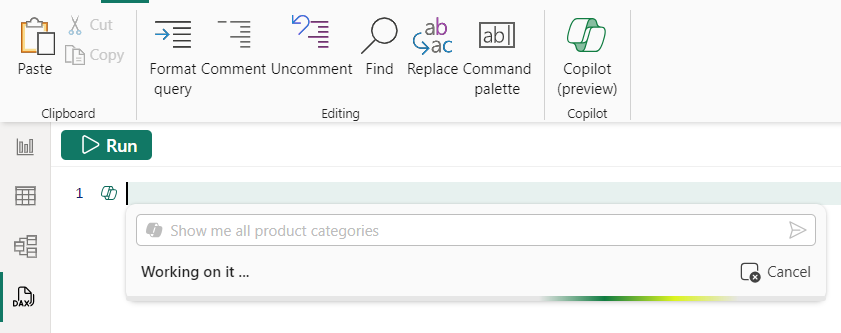
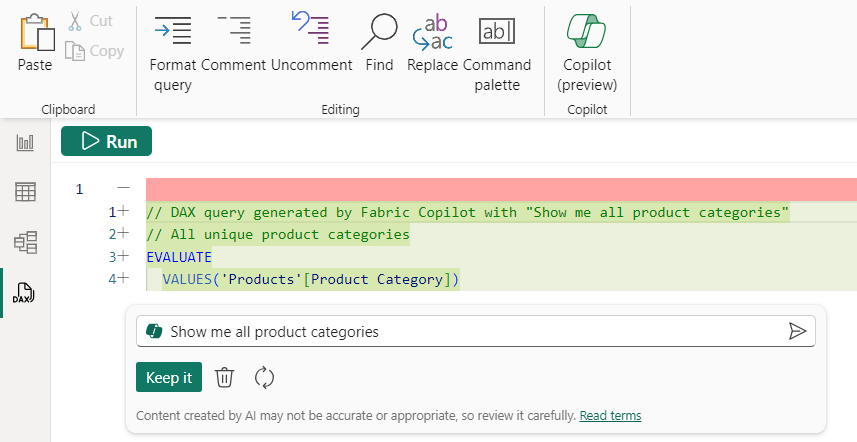
按兩下保留它,然後可以運行查詢以查看結果。
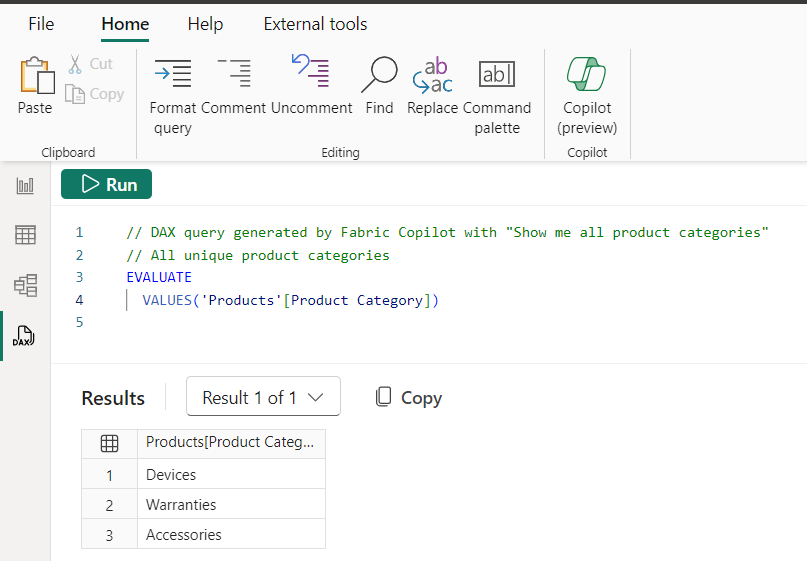
真棒!現在,使用“數據”窗格/“模型資源管理器”,我可以看到模型中已創建的一堆度量值。讓我們看看這些產品類別的樣子。使用 Copilot 調整現有 DAX 查詢。
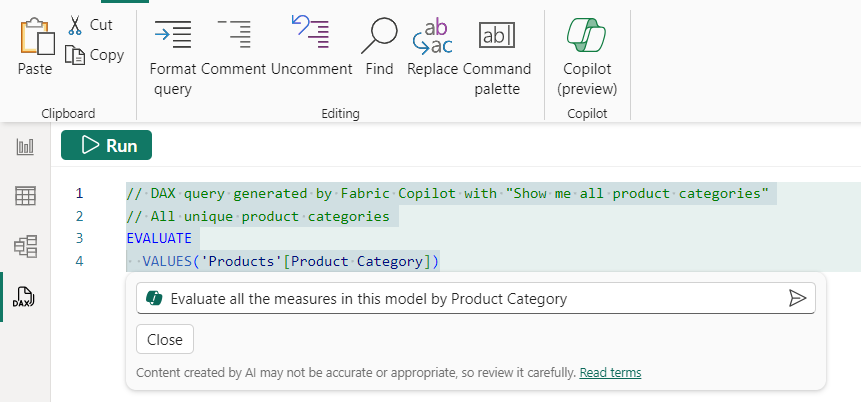
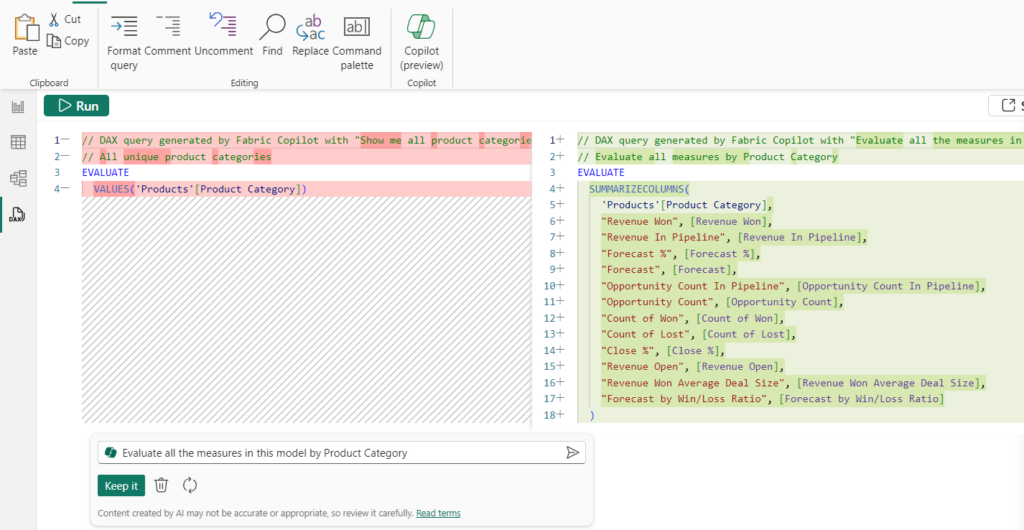
再次,按下“保留它”,然後運行查詢以查看結果。
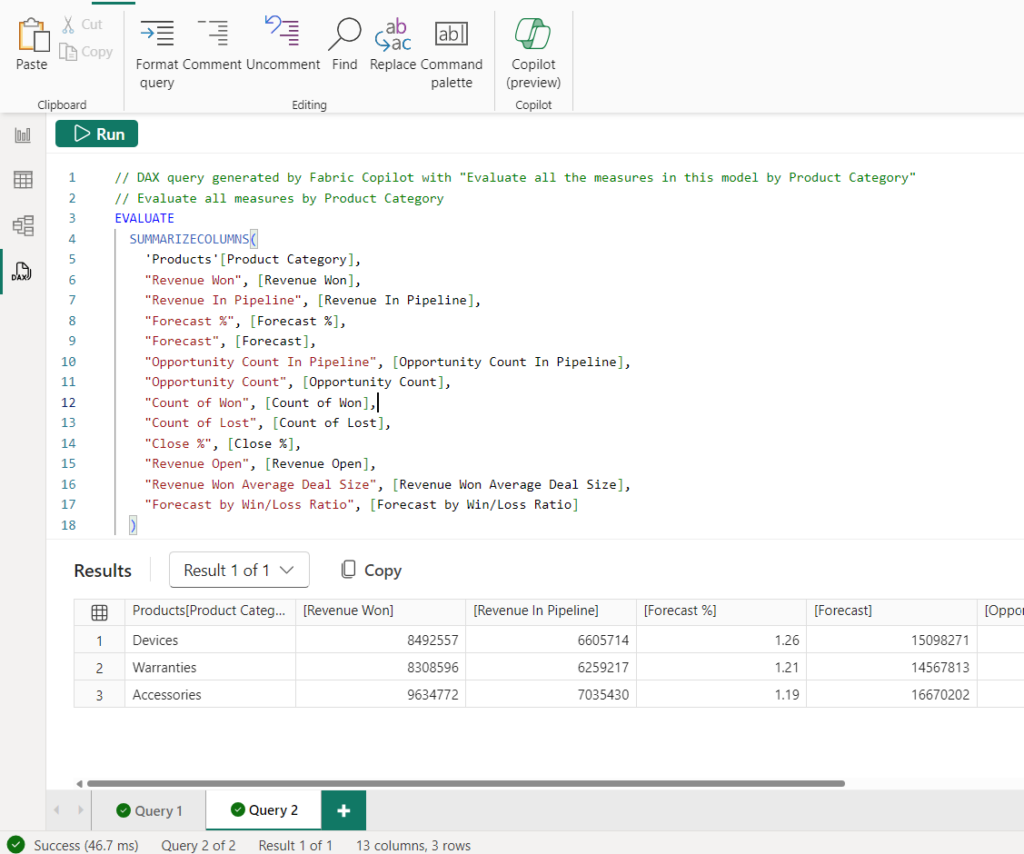
這為我節省了很多時間。以前,我只能看到,如果我轉到報表檢視並創建視覺物件,拖放所有欄位,或者在 DAX 查詢檢視中手動鍵入所有欄位。
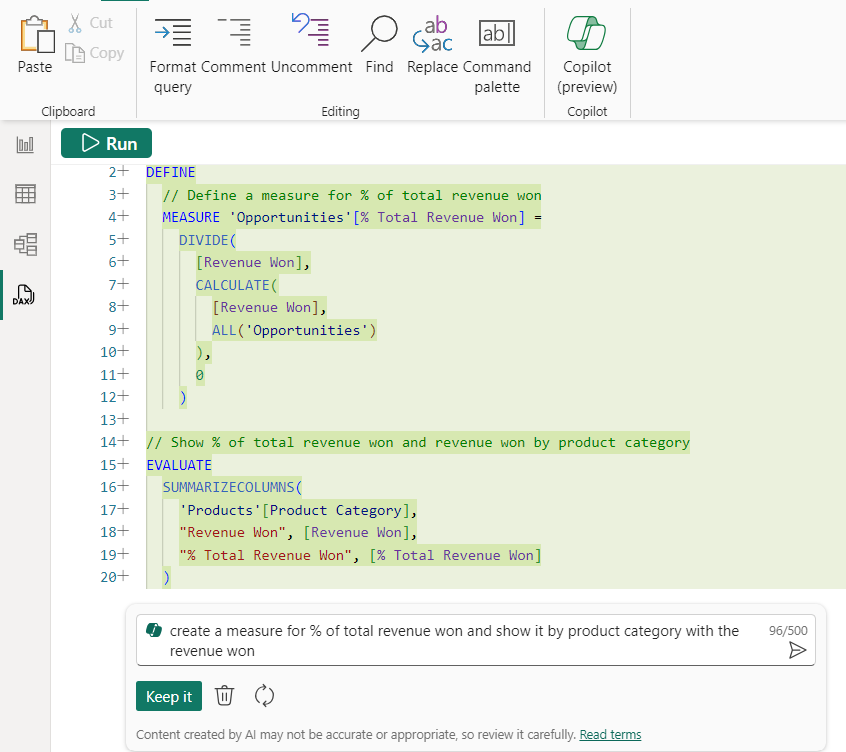
現在,讓我們使用 Copilot 創建新度量。DAX 查詢支援創建度量值的功能,而無需將其添加到模型中。這種創建度量值的有用方法意味著我可以在添加到模型之前對其進行測試,還可以一次編寫多個度量值。現在,讓我們在 Copilot 的幫助下創建一個額外的度量。我想通過添加總收入的百分比來進一步分析按類別贏得的收入。
- 我轉到一個新的查詢選項卡並調用 Copilot(CTRL+I 或編輯器或功能區中的 Copilot 按鈕)。這次我使用“為贏得的總收入的百分比創建一個度量,並按產品類別顯示贏得的收入”
- 這次生成的 DAX 查詢是使用我想要創建的度量值的 DEFINE 塊生成的!
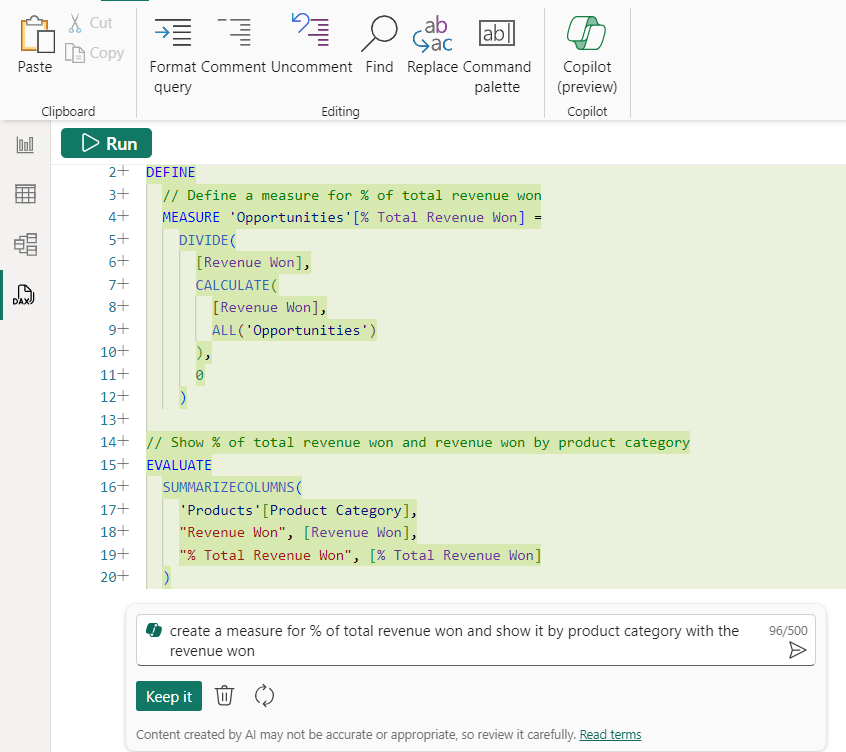
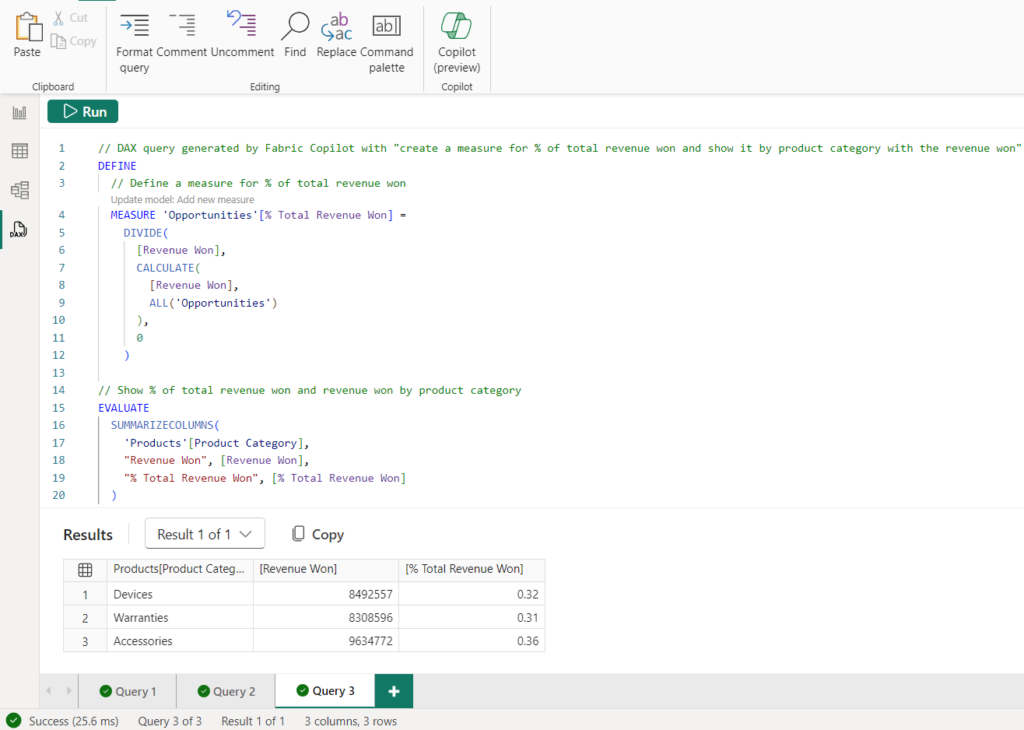
在 DAX 查詢檢視中,當在模型中尚不存在的 DAX 查詢中定義度量值時,有一個 CodeLens 選項,用於通過添加新度量值來更新模型,您可以在第 3 行和第 4 行之間看到該選項。就在我正在做的事情的背景下,我擁有完成工作所需的工具。
說到上下文,當我使用 Copilot 處於 DAX 查詢檢視時,我可以找到有關 DAX 函數或主題的更多資訊。剛剛生成的查詢使用了 ALL 函數。讓我們看看 Copilot 是否可以告訴我更多關於它的資訊。
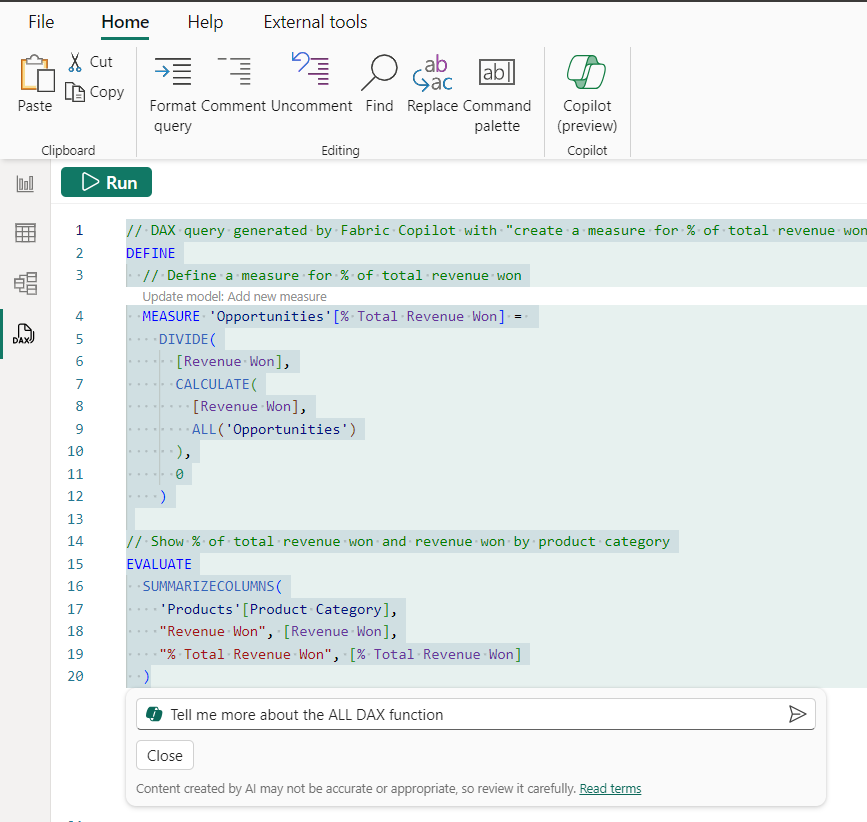
現在,我得到了 ALL DAX 函數的詳細說明,以及它在剛剛生成的 DAX 查詢中的使用方式!
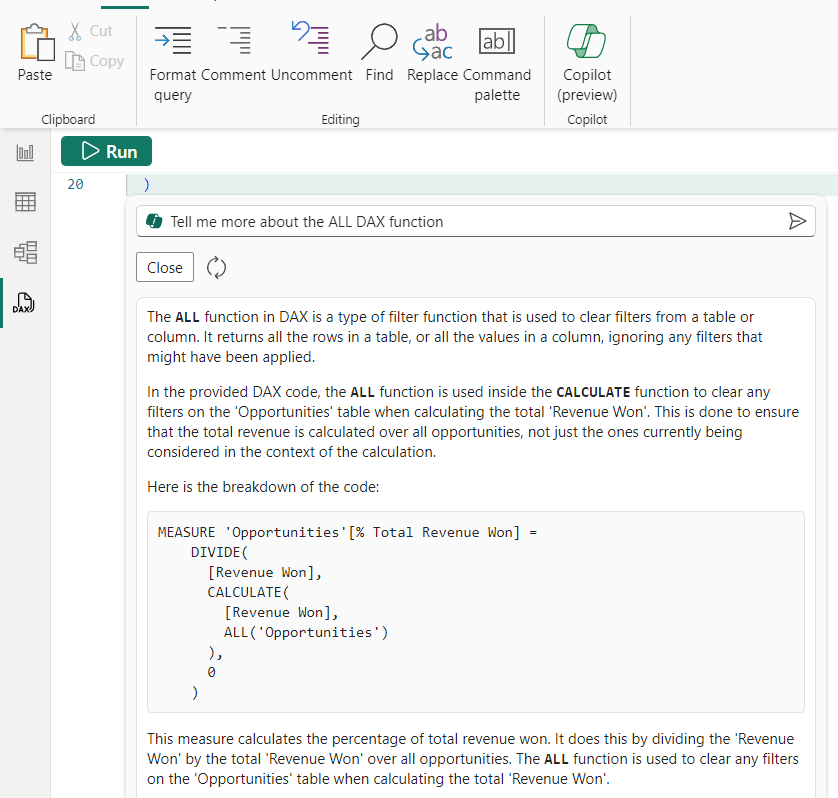
現在,我更多地瞭解了DAX函數,我在哪裡使用它們,以及在我使用它們的模型的上下文中。我可以專注於我的工作,而不會被不同的網站或視頻分心來進一步解釋它,而且我不必聯繫可以向我解釋的朋友。
說到那個可以向我解釋 DAX 函數的朋友,也許他們之前寫了一個 DAX 查詢,現在我不太記得他們說它做了什麼。現在,我將進入最後一個示例:解釋已使用 Copilot 編寫的 DAX 查詢。
- 我已經在 DAX 查詢選項卡上編寫了 DAX 查詢。在此示例中,我執行了快速查詢>在 Territories 表上顯示前 100 行。我選擇 DAX 查詢,調用 Copilot (CTRL + I) 並使用提示“此 DAX 查詢正在做什麼?
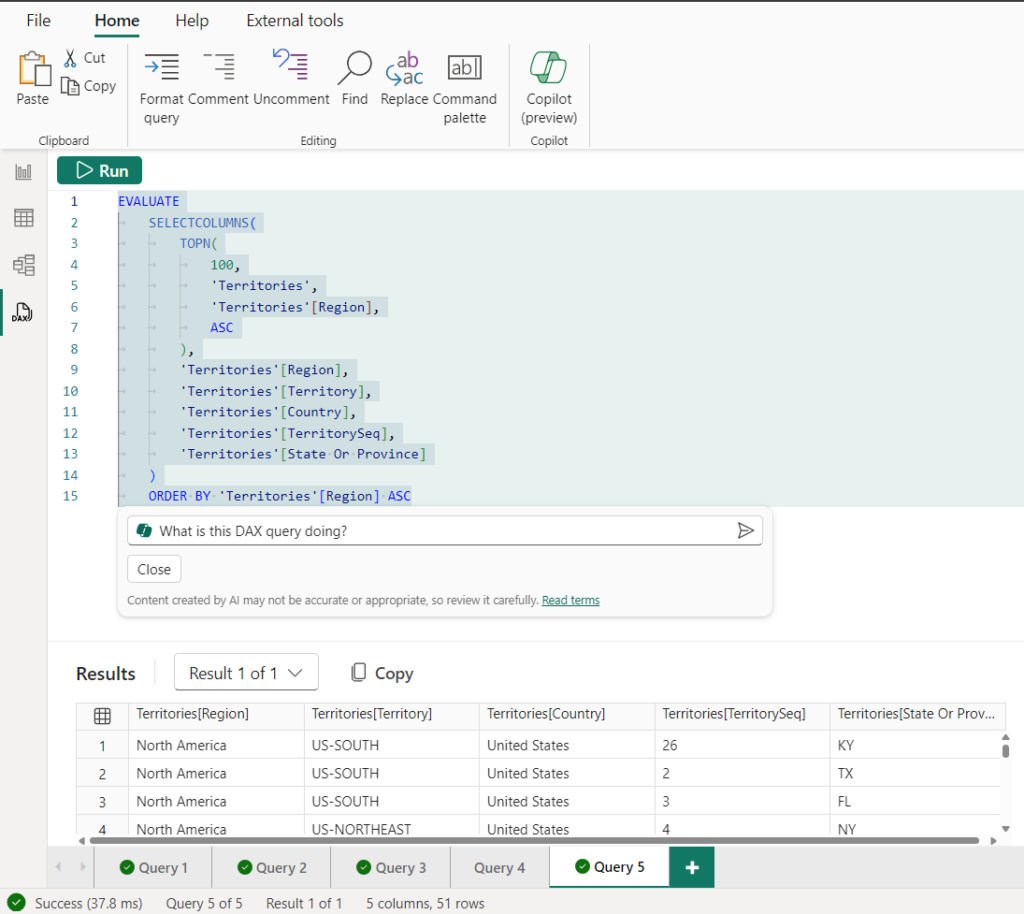
我還得到了 DAX 查詢的詳細說明,以及易於閱讀的格式中的每個部分。
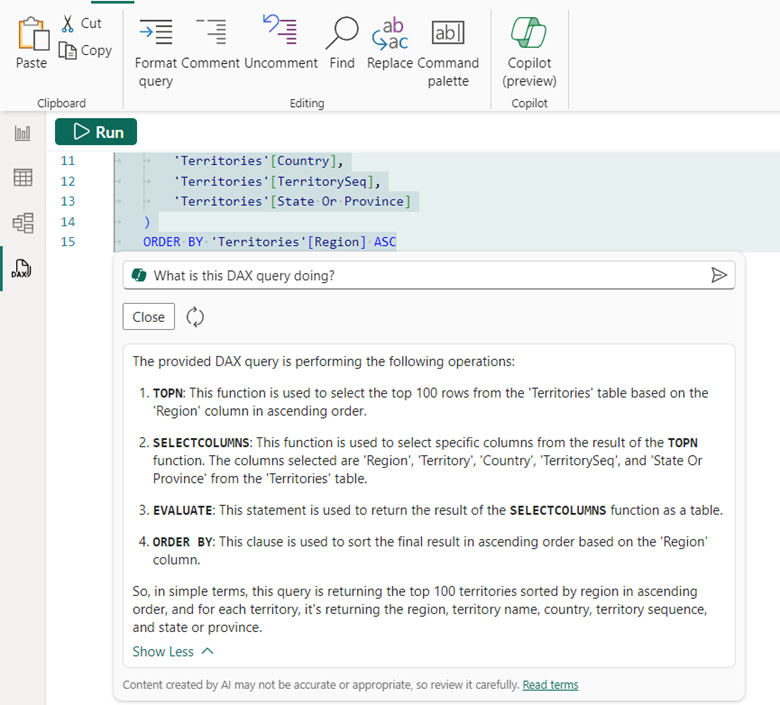
同樣,我仍然處於我正在做的事情的上下文中,以及我正在使用的模型的上下文中。得到答案後,我可以繼續從我離開的地方繼續前進。
此功能應已在最新的 Power BI Desktop 版本(2024 年 3 月或更高版本)中啟用,但可以在“檔>設置和選項”>“選項”>“預覽功能”部分中打開和關閉。
使用 DAX 查詢檢視 Copilot 時需要注意的一些事項。 在公共預覽版期間,我們將進行更改並更新功能和UI,因此這些示例可能會為你返回不同的結果。
- 我們還在分析 Copilot 返回的 DAX 查詢,如果語法不正確,則執行一次重試。在重試也未通過解析器檢查的罕見情況下,我們仍將返回DAX查詢,但請注意存在問題。如果可以看到導致問題的原因,則可以鍵入新提示或調整 DAX 查詢。
- 如上所述,目前運行在您完成內聯 Copilot 之前不起作用,因此在將來的更新中,當 Copilot 處於活動狀態時,運行按鈕將被禁用。
- 我們還在努力解決的最後一個限制是,在你按兩下「保留」之前,內聯 Copilot 不知道前面的提示。例如,如果您要求它創建一個 DAX 查詢以顯示“按年份劃分的銷售額”,那麼它會生成 DAX 查詢,則不能簡單地鍵入“添加產品”來進一步調整它。現在,您必須按下「保留它」,選擇生成的 DAX 查詢,再次調用 Copilot,然後「添加產品」將按預期工作。
所以,今天就試試吧!分享您的反饋並查看下面提供的其他資源。
- 瞭解有關 DAX 查詢的更多資訊,請訪問 https://learn.microsoft.com/dax/dax-copilot 查看 Copilot
- 如需詳細瞭解 DAX 查詢檢視,請存取 https://learn.microsoft.com/power-bi/transform-model/dax-query-view
- 瞭解更多關於Fabric Copilot的資訊,請訪問 https://learn.microsoft.com/fabric/get-started/copilot-fabric-overview
- 詳細瞭解 Power BI 中的 Fabric Copilot,請訪問 https://learn.microsoft.com/power-bi/create-reports/copilot-introduction
- 觀看 Carly 和 Guy in a Cube 在 https://www.youtube.com/watch?v=0kE3TE34oLM 上使用 Copilot 演示 DAX 查詢檢視



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}