


本篇文章引用並翻譯自 Marc Bushong 的 ”Lakehouse vs Data Warehouse vs Real-Time Analytics/KQL Database: Deep Dive into Use Cases, Differences, and Architecture Designs”,最初發表並公開於2023年12月13日 Microsoft Fabric Updates Blog,以下翻譯僅供參考,如有歧義一律以原文為主。引用來源:https://blog.fabric.microsoft.com/zh-tw/blog/lakehouse-vs-data-warehouse-deep-dive-into-use-cases-differences-and-architecture-designs?ft=All
隨著 Microsoft Fabric 在 Ignite 上的全面發佈,有很多問題圍繞著每個元件的功能,但更重要的是,哪些架構設計和解決方案最適合 Fabric 中的分析。具體而言,用於分析數據倉庫/報告的數據資產將如何改變或與現有設計不同,以及如何選擇正確的前進路徑。本文將重點幫助您了解數據倉庫、數據湖倉一體和 KQL 資料庫、結構解決方案設計、倉庫/湖倉一體/即時分析用例之間的差異,並充分利用數據倉庫、數據湖倉一體和即時分析/KQL 資料庫。
本文涵蓋的主題:
- 對 Microsoft Fabric 的進階描述,以建立對體系結構/相關元件的基本瞭解。
- 數據倉庫、數據湖倉一體、即時分析/KQL 資料庫和 OneLake 的進階說明。
- 數據倉庫、數據湖倉一體和即時分析/KQL 資料庫之間的區別。
- 數據倉庫、數據湖倉一體、即時分析/KQL 資料庫的用例,或共同使用時的情況。
- 用於使用數據倉庫、數據湖倉一體和即時分析/KQL 資料庫的體系結構設計。
什麼是 Microsoft Fabric?
Microsoft Fabric 是企業級的一體化分析解決方案,涵蓋從數據移動到數據科學、即時分析和商業智慧的所有內容。它提供一整套服務,包括數據湖、數據工程和數據集成,所有都集中在一個地方。

Microsoft Fabric 建立在 SaaS 基礎之上,因為它將 Power BI、Azure Synapse 和 Azure 數據工廠中的新元件和現有元件整合到單個集成環境中。可以通過數據工程、數據工廠、數據倉庫、數據科學、即時分析和Power BI等體驗在這些元件上進行交互/構建。在一個共用平台上擁有這些元件/體驗的優點是:
- 行業內廣泛的深度集成分析。
- 在熟悉且易於學習的體驗之間共享體驗。
- 開發人員可以輕鬆訪問和重用所有資產。
- 一個統一的數據湖,允許您在使用首選分析工具的同時將數據保留在原處。
- 跨所有體驗的集中管理和治理。
儘管 Fabric 的元件使用“Synapse”作為數據工程、數據倉庫、數據科學和即時分析的前綴 → 但這與 Azure Synapse Analytics 不同。由於命名,這可能會導致混淆。該技術建立在 Synapse 現有技術之上,但架構 / 功能有很多重大變化 / 改進,使其成為革命性的版本。具有 Azure Synapse Analytics(專用池、無伺服器池、Spark 池)經驗的用戶會發現 Microsoft 結構元件的概念很熟悉,但技術/ 功能已得到顯著改進和優化。
什麼是 OneLake、數據湖倉一體、數據倉庫和即時分析/KQL 資料庫?
OneLake
OneLake 是數據湖,是構建所有 Fabric 服務的基礎。OneLake 基於 ADLS (Azure Data Lake Storage) Gen2 和服務構建,作為租戶範圍的數據存儲,可以支援任何類型的檔案(結構化或非結構化檔)。每個 Fabric 租戶都會自動預配 OneLake,無需設置或管理額外的資源。所有 Fabric 數據項(如數據倉庫和湖倉一體)都會以 Delta Parquet 格式自動將其數據存儲在 OneLake 中。
它是所有開發人員(專業人員和公民)的單一統一存儲系統,集中且統一地執行所有合規性、安全性和策略。OneLake 消除了跨組織的數據孤島,並且無需物理複製或移動數據供不同的團隊/引擎使用,無論數據是在 OneLake 中還是存儲在快捷方式相容位置。您可以將 OneLake 視為用於組織數據的 OneDrive。
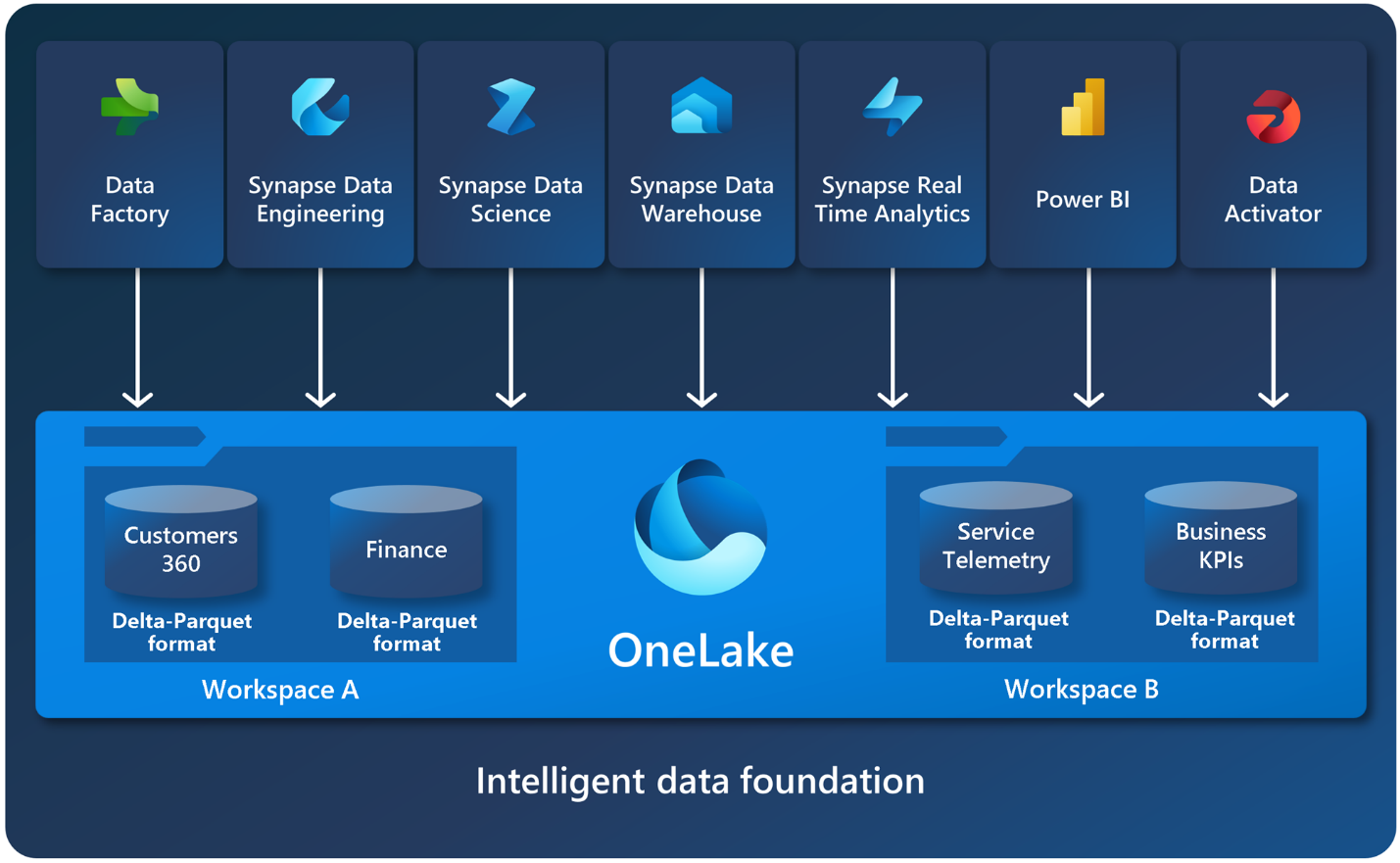
數據湖倉一體(Data Lakehouse)
Microsoft Fabric Lakehouse 是一個數據體系結構平台,用於在單個位置以開放格式存儲、管理和分析結構化和非結構化數據。默認檔案格式為 delta parquet。您可以將資料儲存在自動預配的 2 個物理位置:即檔案(非託管)或表格(託管Delta表)中。
- 表格
- 用於在Spark中託管所有格式的表格(CSV、Parquet 或 Delta)的託管區域。所有表格(無論是自動創建的還是顯式創建的)都將被識別為 Lakehouse 中的表格。此外,任何 Delta 表格(即具有基於文件的事務日誌的 Parquet 數據檔)也被識別為表格。
- 檔案
- 用於以任何檔案格式存儲數據的非託管區域。存儲在此區域中的任何 Delta 檔都不會自動識別為表。如果要在非託管區域中的 Delta Lake 資料夾上創建表格,則需要顯式創建快捷方式或外部表格,其位置指向 Spark 中包含 Delta Lake 檔的非託管資料夾。
Lakehouse 允許您通過 Spark 計算執行轉換,或使用 SQL 端點來分析/瀏覽數據。Data Lakehouse 的默認檔格式是 delta parquet,最適合分析工作負載性能。
數據湖倉一體並不是 Microsoft Fabric 的新概念或專有概念,因為它們在使用推薦的medallion架構的分析工作負載體系結構中非常常見(稍後會詳細介紹)。數據湖倉一體的相同概念也存在於 Microsoft Fabric 中,具有一些新功能,並與 Microsoft Fabric 內部的元件以及 Microsoft Fabric 外部的其他一些服務無縫集成。包括提供一份數據副本並在其他團隊之間共用、且零數據重複的能力。
數據倉庫(Data Warehouse)
Microsoft Fabric 數據倉庫是基於企業級分散式處理引擎構建的以湖為中心的數據倉庫。與其他數據倉庫解決方案相比,Fabric Data Warehouse 的主要優勢之一是,由於倉庫使用 OneLake 作為其存儲,因此無需從數據倉庫複製數據供其他計算引擎或團隊使用,以 delta parquet 格式存儲在 Microsoft OneLake 中的數據的一個副本。因此,您可以進行跨資料庫查詢,無縫地利用不同的來源(OneLake 或其他通過快捷方式的來源)的數據,而且沒有數據重複。
數據倉庫的核心是具有 Delta 表格和 TDS 端點的 SQL MPP 引擎(大規模並行處理引擎),它將為您提供完整的 T-SQL DDL 和 DML 支援(檢查特定功能/特性的可用性)。計算是一種無伺服器基礎結構,允許通過動態資源分配進行無限擴展,在不涉及物理預配的情況下即時擴展或縮減,並在幾毫秒內將物理計算資源分配作業。
即時分析/KQL 資料庫(Real-Time Analytics/KQL Database)
Real-Time Analytics(即時分析) 是一個完全託管的大數據分析平台,針對流式處理和時間序列數據進行了優化。它利用具有卓越性能的查詢語言和引擎來搜索結構化、半結構化和非結構化數據。Real-Time Analytics 與整套 Fabric 產品完全集成,適用於數據載入、數據轉換和高級可視化方案。就像其他 Microsoft Fabric 元件一樣,即時分析是一種 SaaS 體驗。
借助 Microsoft Fabric 中的即時分析,您可以使組織能夠專注於和擴展其分析解決方案,同時使數據民主化,以滿足公民數據科學家和高級數據工程師的需求。即時分析在企業領域的許多場景中都變得至關重要,例如網路安全、資產跟蹤和管理、預測性維護、供應鏈優化、客戶體驗、能源管理、庫存管理、品質控制、環境監控、車隊管理以及健康和安全。這是通過降低數據集成的複雜性來實現的。您可以在幾秒鐘內獲得數據洞察的快速訪問,實現對任何數據源或格式的自動數據流、索引和分區(任何數據源或格式)以及按需查詢生成和可視化。即時分析可讓您專注於分析解決方案,隨著數據和查詢需求的增長,通過該服務無縫擴展。
閱讀更多有關即時分析的獨特之處,並了解即時分析的優勢請參考: 是什麼讓即時分析與眾不同?
即時分析使用 KQL 資料庫作為數據存儲。本文稍後將介紹即時分析解決方案的體系結構/元件,但現在我將簡要概述 KQL 資料庫。KQL 代表 Kusto 查詢語言,它是一種查詢語言,用於與位於 KQL 資料庫中的數據進行交互。KQL 資料庫可用作適用於 Fabric Real-Time Analytics 和 Azure 資料資源管理器的通用術語,因為它指的是使用 KQL 與之交互的資料庫/存儲。
即時分析的核心是與 Azure 數據資源管理員共用相同的核心引擎和相同的核心功能,只是管理行為不同。(Azure 數據資源管理器是 PaaS 產品/服務,即時分析是 SaaS 產品/服務)。因此,如果您熟悉 Azure 數據資源管理器,則該知識可轉換為 Fabric 即時分析,但在管理方面存在一些差異。
Azure 數據資源管理器為引入和查詢遙測數據、日誌、事件、跟蹤和時序數據提供了無與倫比的性能。它具有優化的儲存格式和索引,並使用高級數據統計資訊實現高效的查詢規劃和即時編譯的查詢執行。Azure 資料資源管理器提供數據快取、文字索引、行存儲、列壓縮、分散式數據查詢、存儲和計算分離。
請參閱此文檔,查看即時分析和 Azure 數據資源管理器之間的功能/管理差異:即時分析和 Azure 數據資源管理器之間的差異 – Microsoft 結構 | Microsoft 學習
數據湖倉一體、數據倉庫和即時分析/KQL 資料庫之間有什麼區別?
現在,我們已經對 Microsoft Fabric 是什麼有了基本的且深度的瞭解,特別是 OneLake、Data Lakehouse、數據倉庫和即時分析/KQL 資料庫。現在是時候分解數據湖倉一體、數據倉庫和即時分析/KQL 資料庫之間的差異了,以便更好地瞭解每個用例並幫助我們設計解決方案。
首先,我們將重點介紹數據湖倉一體和數據倉庫之間的比較,然後再比較即時分析/KQL 資料庫。
Data Lakehouse 和 Data Warehouse 都是開放數據格式——delta parquet、以湖為中心的方法,並且具有一些交叉功能,但有一些差異,我已將其細分為幾類。
- 如何訪問/處理數據
- 正在使用的端點(詳見下文)
- 存儲/使用的數據類型
- 開發人員技能組合
數據湖倉一體和數據倉庫的端點
Lakehouse 和 Data Warehouse 之間有 3 個不同的端點。
- Spark 運行時/庫的 Lakehouse 端點
- Lakehouse 的 SQL Analytics 端點
- 數據倉庫端點
Spark 運行時/庫的 Lakehouse 端點
若要使用 Spark 與 Lakehouse 檔/表進行交互以進行分析、轉換或處理,需要連接到獨立於 SQL Analytics 端點的 Lakehouse 端點。就像 Fabric 外部用於與檔/delta表交互的標準方法一樣,您將使用 URL、ABFS 路徑或直接在資源管理員中掛載 Lakehouse 進行連接。使用 Spark 可以使用所選的 Scala、PySpark、Spark SQL 或 R 執行寫入操作。但是,如果要使用 T-SQL,則需要使用 SQL Analytics 端點,在其中只能執行只讀操作。
Lakehouse 的 SQL Analytics 端點
此端點為 Lakehouse Delta表提供基於 SQL 的體驗。SQL Analytics 端點提供了使用 SQL 在 Lakehouse 中交互、查詢和提供數據的功能。此體驗是唯讀的,僅適用於delta表。這將是 Lakehouse 的「表(Tables)」部分,而「檔(Files)」部分無法通過 SQL 終端讀取/發現。SQL Analytics 端點允許使用 T-SQL 分析delta表、保存函數、生成檢視以及應用 SQL 物件級安全性。它使數據工程師能夠在 Lakehouse 中的物理數據之上構建關係層,並使用 SQL 連接字串將其公開給分析和報告工具。
創建指向delta表存儲的 Lakehouse 時,會自動創建 SQL Analytics 端點。每個 Lakehouse 只有一個 SQL 端點,每個工作區可以有多個 Lakehouse。這意味著工作區中的 SQL 端點數量與湖倉一體的數量相匹配。
請務必注意,delta表(以及delta表中的數據)的創建/修改必須使用 Apache Spark 完成,通過 Lakehouse 中的 Spark 創建的delta表可通過端點自動發現。如果存在使用Spark代碼創建的外部delta表,則它們對SQL分析端點不可見,直到創建外部dekta表的快捷方式才能使其可見。
可以設置物件級安全性,以便使用 SQL 分析端點存取資料。這些安全規則僅適用於通過 SQL 分析端點訪問數據。這意味著,如果要確保無法通過其他方式(通過不同的端點或直接)訪問數據,則必須設置工作區角色和許可權。
可以通過提供身份驗證和端點連接字串,在 Fabric 外部以及使用 SSMS 或 Azure Data Studio 等工具連接到此端點,就像任何其他 SQL Server 連接一樣。
在後台,SQL 分析端點使用與倉庫端點相同的引擎來提供高性能、低延遲的 SQL 查詢。這意味著它也是一個 TDS 端點,只是與數據倉庫端點相比,它對 DML/DDL 功能和 T-SQL 圖面有限制。
請務必注意,MSFT 文件會將 Lakehouse 的 SQL Analytics 端點描述為數據倉庫。儘管根據上下文,這可能是正確的,但我不會將其稱為數據倉庫,以避免在討論 Synapse 數據倉庫時產生混淆。我將通過 SQL Analytics 端點或 Lakehouse 上的 SQL 查詢顯式引用它。
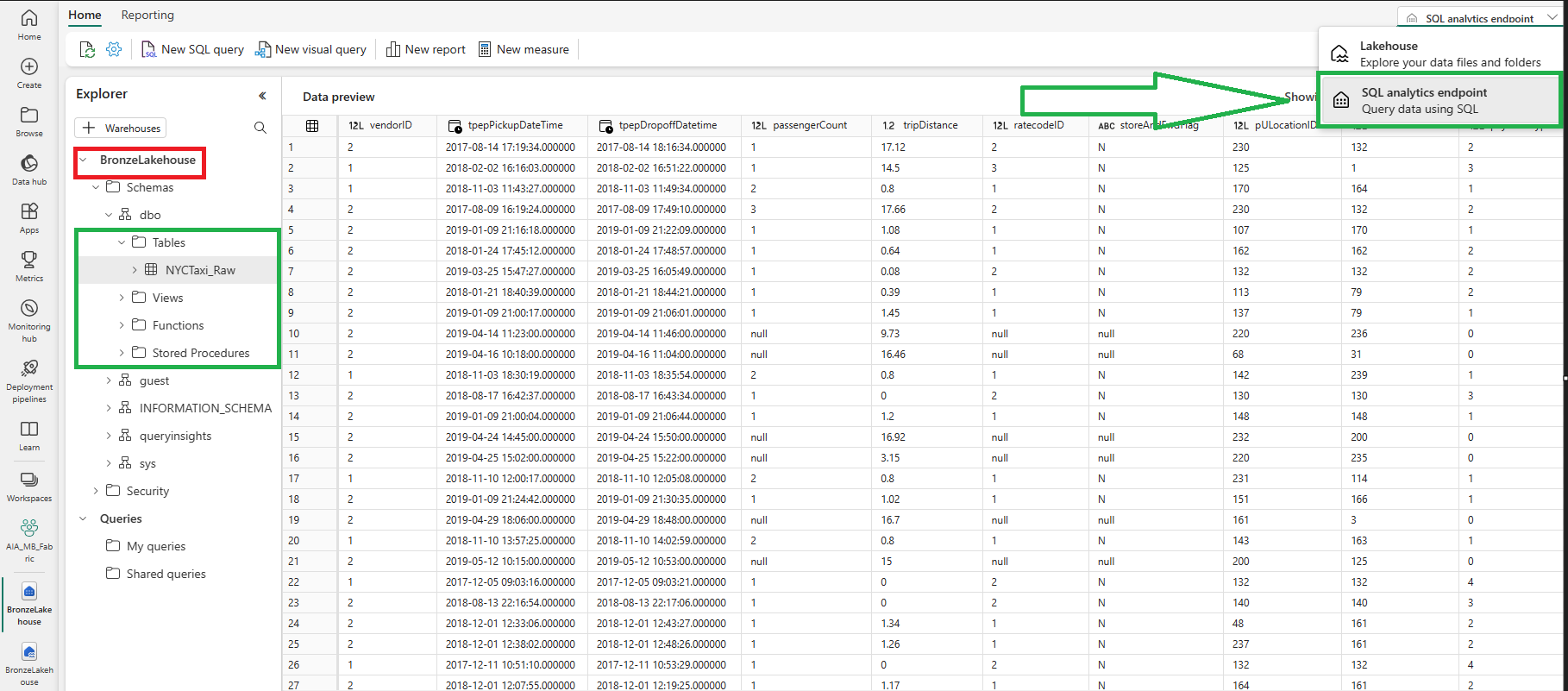
在我的 Fabric 工作區中,我有一個名為“BronzeLakehouse”的 Lakehouse。在那個湖屋中,我有 2 個與我的湖屋相關的專案(不同的項目類型)。SQL Analytics 端點(紅色)和 Lakehouse 端點(綠色)
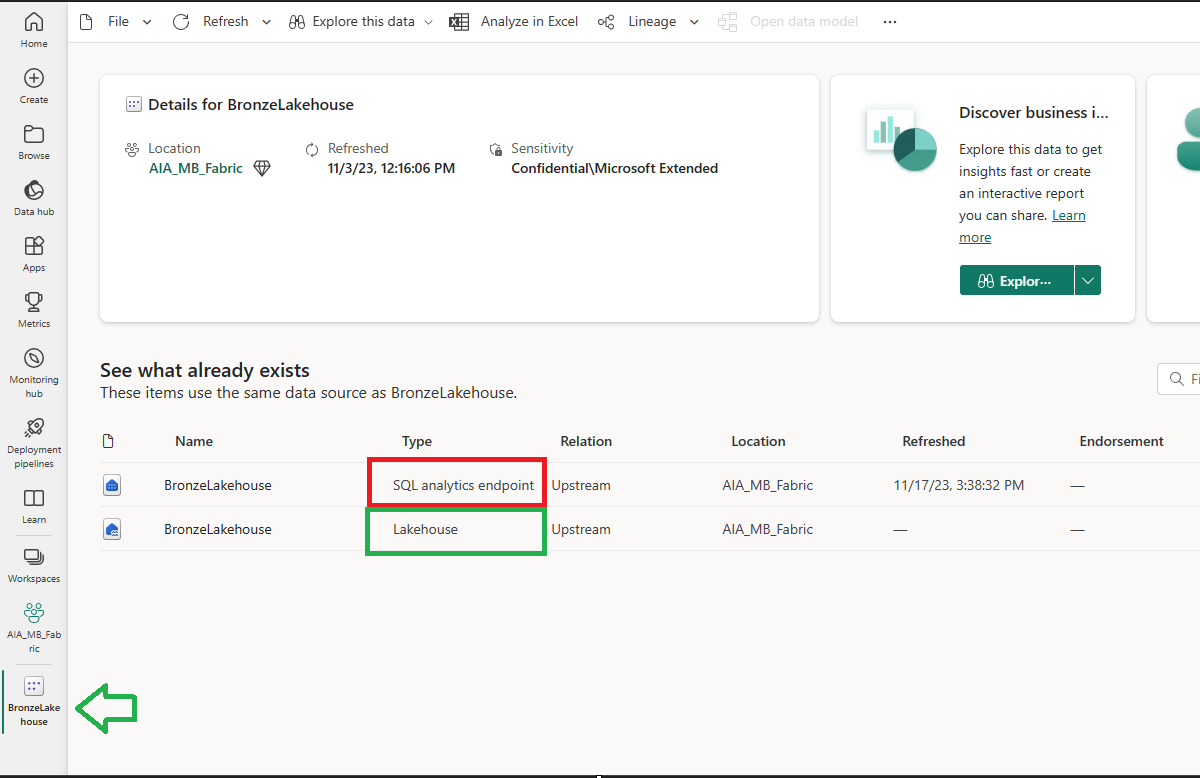
使用「Lakehouse」端點可以看到什麼?檔案(紅色)和delta表(綠色)。您可以通過下拉選項(顯示展開)在右上角查看目前正在查看的端點
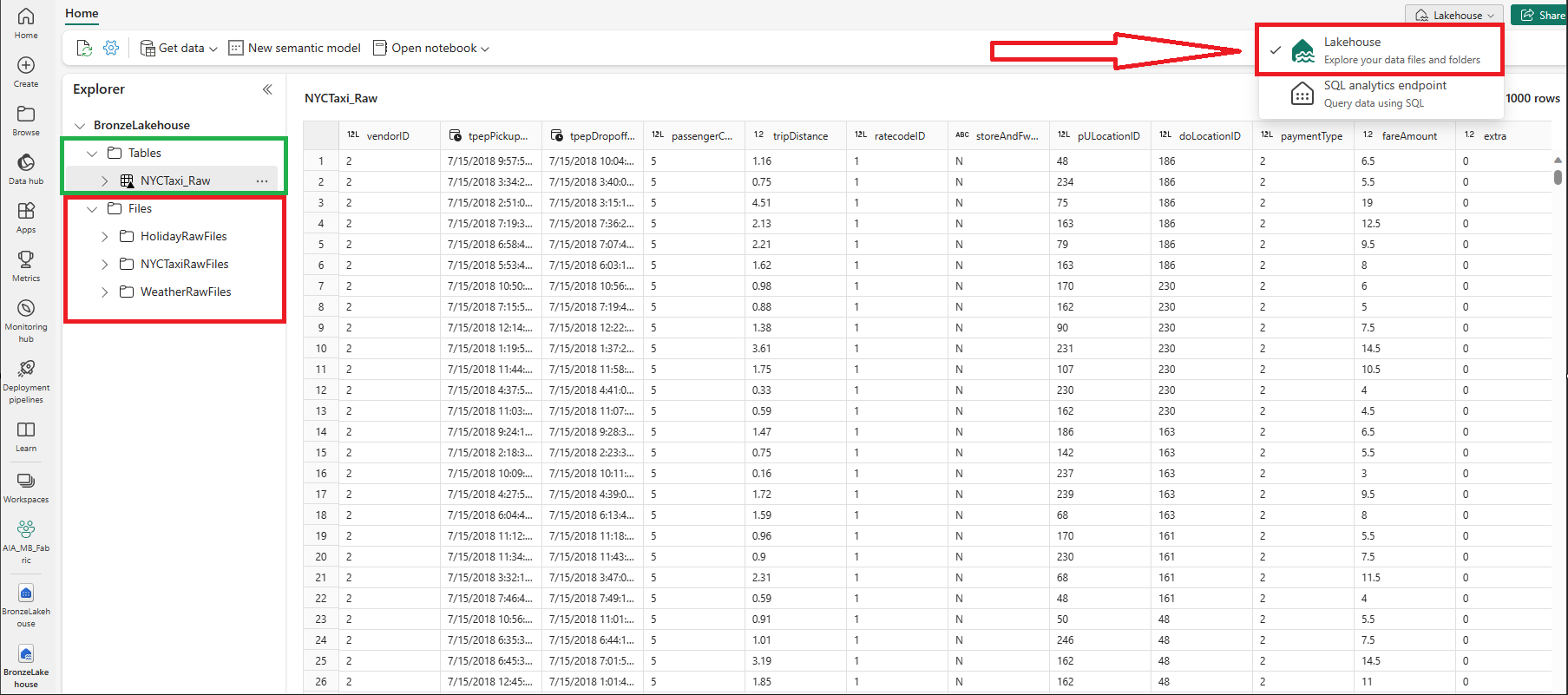
使用 Lakehouse 的 SQL Analytics 端點可以看到什麼?僅限delta表。
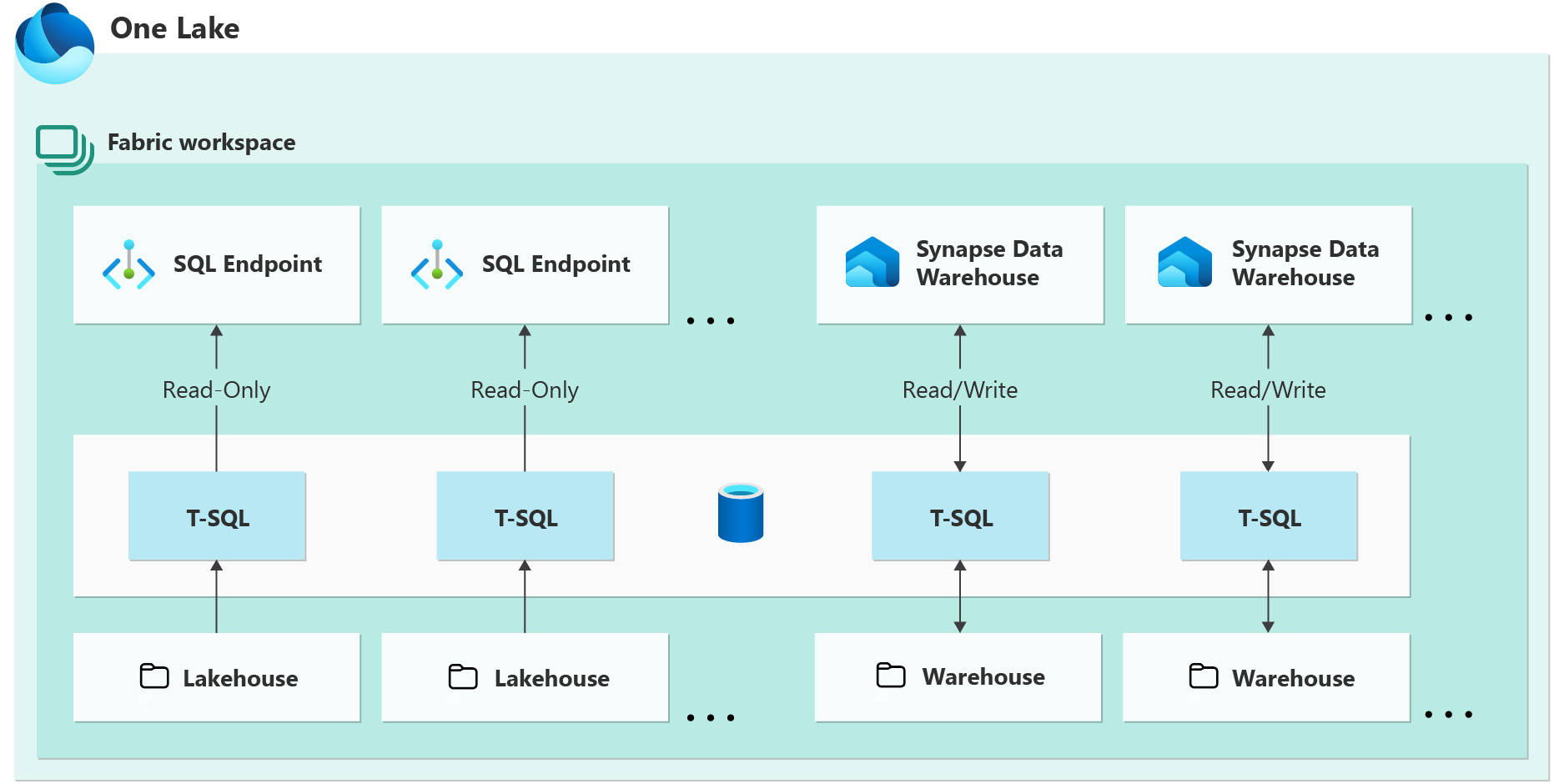
數據倉庫端點(Data Warehouse Endpoint)
Synapse 數據倉庫或倉庫端點以「傳統」SQL 數據倉庫方式運行。這意味著此端點支援完整的 T-SQL 功能,例如企業數據倉庫。與 SQL Analytics 端點不同,數據倉庫端點提供:
- 對delta表的讀取和寫入支援
- 可以使用spark或T-SQL讀取數據
- 只能使用 T-SQL 寫入數據
- 完整的 DML 和 DDL T-SQL 支援
- 包括通過 TSQL 或 UI 進行數據引入、建模和開發
- 您可以完全控制建立表、載入和轉換
- 可以使用 COPY INTO、管道、數據流或使用 CREATE TABLE AS SELECT (CTAS)、INSERT..INTO 或 SELECT..INTO 進行跨資料庫引入。
- 完整的 ACID 兼容性 並支援交易
- Lakehouse 僅對 Delta Tables 提供 ACID 合規性支援。因此,湖倉一體中可能存在不支援 ACID 比較的檔/數據。
- 多表事務支援
將完整的讀/寫功能與跨資料庫引入功能相結合,可以無縫地從多個數據倉庫或湖倉一體進行引入。將數據引入數據倉庫時,它將創建一個存儲在 OneLake 中的Delta表。
下面是一個關係圖,可幫助解釋 SQL Analytics 端點和數據倉庫端點之間的區別。
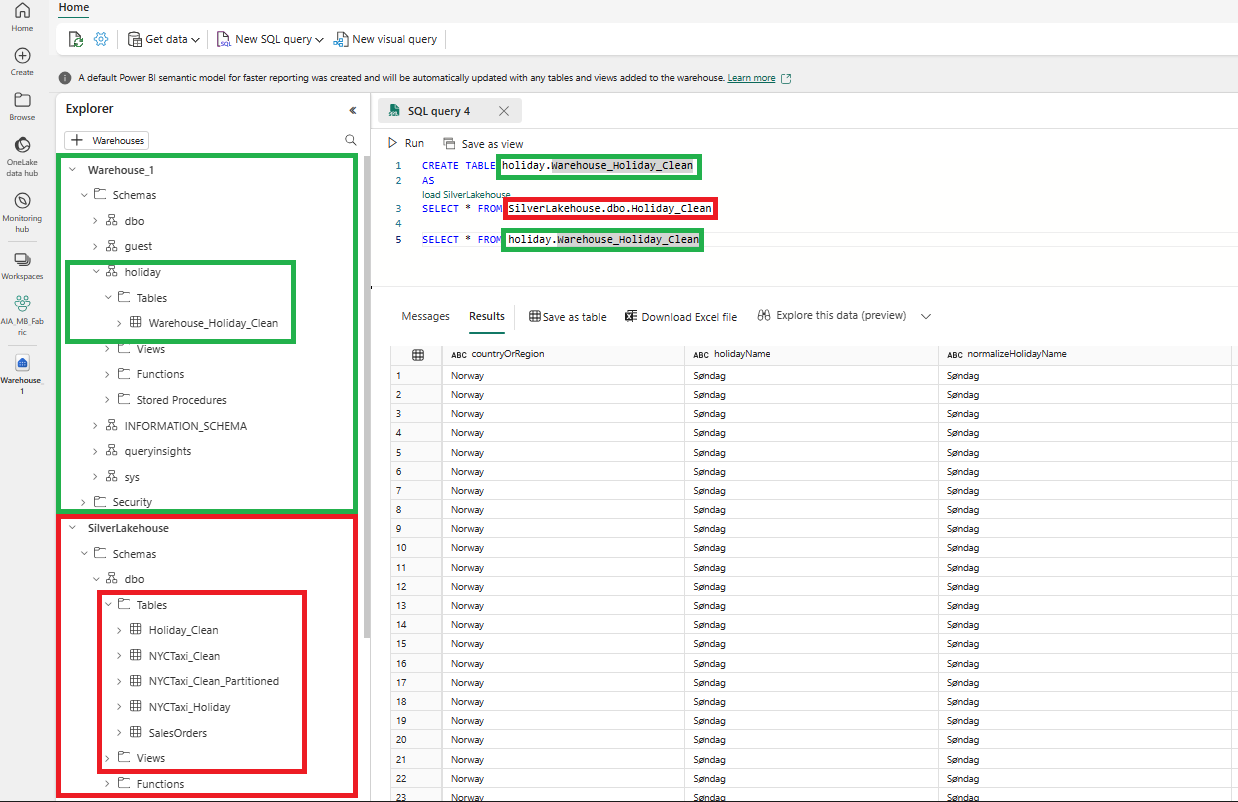
用於將數據從 Lakehouse 載入資料倉庫的跨資料庫查詢範例。
倉庫表『holiday.Warehouse_Holiday_Clean“是創建並使用 CTAS 語句,將”SilverLakehouse.dbo.Holiday_Clean“ delta表作為來源載入。
KQL 資料庫端點(KQL Database Endpoint)
KQL 資料庫不是一個新概念,也不像 Lakehouse 或數據倉庫的端點那樣複雜。我們將討論將即時分析/KQL 資料庫與其他產品區分開來的用例和其他因素,但本部分針對的是端點的差異。
讀/寫功能沒有限制,具體取決於語言或端點,因為 KQL 資料庫沒有不同的端點。您將能夠使用 KQL、Spark、連接器生態系統(無代碼)或 T-SQL 進行讀/寫。根據您要執行的確切操作,可能會有更好的語言或流程,您必須根據具體情況進行評估。
讀/寫功能的限制將應用於帳戶許可權。KQL 資料庫提供僅應用行級別安全性的功能,該安全性是特定於帳戶的,而不是特定於計算引擎的,如數據倉庫和 Lakehouse。
下面是我想強調的使用 KQL 資料庫的一些主要好處:
- 管理無限量的數據,從千兆位元組到拍兆位元組不等,併發查詢和併發使用者具有無限的擴充性。
- 內置的自動縮放功能可調整資源以匹配緩存、記憶體、CPU 使用率和引入等工作負載因素,從而優化性能並最大限度地降低成本。
- 無需轉換即可查詢原始數據,具有高性能、極低的響應時間,同時使用各種可用的運算符。排隊和流式引入有幾秒鐘的延遲。
- 自動對攝取的數據進行索引和分區,以進一步支援無限規模的高性能,而無需像傳統 RDMS 那樣進行管理。
- 任何數據格式都可以通過分析查詢(如自由文本和 JSON 結構)進行攝取/分析。
- 支援高級分析,例如時間序列本機元素以及完整的地理空間存儲和查詢功能
還有一個稱為「一個邏輯副本(One Logical Copy)」的預覽功能。這使您能夠通過在 OneLake 中啟用資料可用性來創建 KQL 資料庫數據的一個邏輯副本。在 OneLake 中啟用 KQL 資料庫的數據可用性意味著可以在 KQL 資料庫中以高性能和低延遲查詢數據,並通過其他構造引擎(如 Power BI、倉庫、湖倉一體、筆記本等中的 Direct Lake 模式)以 Delta Lake 格式查詢相同的數據。
一個邏輯副本(預覽版) – Microsoft Fabric |Microsoft 學習
存儲的數據類型
Data Lakehouse、Data Warehouse 和 KQL 資料庫之間的另一個區別是存儲的數據類型及其組織方式。
在數據湖倉一體中:
- 您可以儲存非結構化、半結構化或結構化數據。
- 數據按資料夾和檔、湖資料庫和delta表進行組織。
在資料主目錄中:
- 您可以儲存結構化數據。
- 數據按資料庫、架構和表(後台的delta表)進行組織
在 KQL 資料庫中:
- 您可以儲存非結構化、半結構化或結構化數據。
- 數據按資料庫、架構和表進行組織。
開發人員技能組合
在許多架構和設計會議中,由於團隊成員的技能組合,正確的服務/模式可能不是最適合您的團隊的。例如,在Spark中轉換數據可能是性能、成本等方面的最佳設計選擇。但是,團隊中沒有人具有Spark或除T-SQL以外的任何語言的經驗或知識。這將影響您的設計,以考慮開發人員技能的可用性/用途。
在數據湖倉一體中:
- 主要技能是Spark(Scala,PySpark,Spark SQL,R)
- 這適用於寫入操作和大多數工作負載
- 借助 Lakehouse 上的 SQL Analytics 端點,可以提供 T-SQL 的輔助技能,用於唯讀操作或分析
- 與數據的交互將主要通過Spark筆記本和Spark作業定義進行。
在資料主目錄中:
- 主要技能是 SQL
- 這包括 T-SQL 和相關的 SQL 知識,如數據建模、DDL/DML 語句、SQL MPP 引擎理解、SQL DBA 知識等。
- 與數據的交互將通過 SQL 腳本進行。
- 存儲過程、檢視、即席查詢等。
- 可以使用 Spark 從數據倉庫讀取數據,但不會將其用於使用/提供。
在 KQL 資料庫中:
- 主要技能是 KQL、SQL 或無代碼。
- 您將能夠使用 KQL、T-SQL、Spark 和 Power BI 讀取數據
- 您將能夠使用 KQL、Spark 和連接器生態系統寫入數據。
- 與數據的交互將直接通過 KQL 查詢集或 KQL 資料庫進行。
下面是一個圖表,用於比較數據倉庫、Lakehouse 和 KQL 資料庫。您可以在此處查看完整文件:結構決策指南 – 選擇數據存儲 – Microsoft Fabric |Microsoft 學習
| Data warehouse | Lakehouse | KQL Database | |
| Data volume | Unlimited | Unlimited | Unlimited |
| Type of data | Structured | Unstructured,semi-structured,structured | Unstructured, semi-structured, structured |
| Primary developer persona | Data warehouse developer, SQL engineer | Data engineer, data scientist | Citizen Data scientist, Data engineer, Data scientist, SQL engineer |
| Primary developer skill set | SQL | Spark(Scala, PySpark, Spark SQL, R) | No code, KQL, SQL |
| Data organized by | Databases, schemas, and tables | Folders and files, databases, and tables | Databases, schemas, and tables |
| Read operations | Spark,T-SQL | Spark,T-SQL | KQL, T-SQL, Spark, Power BI |
| Write operations | T-SQL | Spark(Scala, PySpark, Spark SQL, R) | KQL, Spark, connector ecosystem |
| Multi-table transactions | Yes | No | Yes, for multi-table ingestion. See update policy. |
| Primary development interface | SQL scripts | Spark notebooks,Spark job definitions | KQL Queryset, KQL Database |
| Security | Object level (table, view, function, stored procedure, etc.), column level, row level, DDL/DML, dynamic data masking | Row level, table level (when using T-SQL), none for Spark | Row-level Security |
| Access data via shortcuts | Yes (indirectly through the lakehouse) | Yes | Yes |
| Can be a source for shortcuts | Yes (tables) | Yes (files and tables) | Yes |
| Query across items | Yes, query across lakehouse and warehouse tables | Yes, query across lakehouse and warehouse tables;query across lakehouses (including shortcuts using Spark) | Yes, query across KQL Databases, lakehouses, and warehouses with shortcuts |
| Advanced analytics | Time Series native elements, Full geospatial storing and query capabilities | ||
| Advanced formatting support | Full indexing for free text and semi-structured data like JSON | ||
| Ingestion latency | Queued ingestion, Streaming ingestion has a couple of seconds latency |
數據倉庫、數據湖倉一體和即時分析/KQL 資料庫的用例
現在,對數據倉庫、數據湖倉一體和即時分析/KQL 資料庫之間的差異有了更深入的瞭解,是時候查看一些用例以確定要使用的選項了。有很多具體的用例,不可能涵蓋所有可能的場景,所以我將介紹一些常見場景。
若要確定是僅單獨使用 Lakehouse、單獨使用數據倉庫、單獨使用 KQL 資料庫,還是將它們混合在一起,通常取決於解決方案的這些要求。
- 數據將如何被消耗/使用
- 應用程式或 ETL/ELT 的要求
- 開發人員的技能組合
- 包括數據工程師、數據科學家、公民開發者和專業開發者
數據將如何被消耗/使用
在設計解決方案時,瞭解您正在使用的數據將如何被消耗非常重要。Lakehouse、Data Warehouse 和 KQL Database 在向使用者提供數據方面具有很大的靈活性/重疊能力。但是,具體需求/細微差別可能因解決方案而異,因此下面是數據的不同使用方法的一些常見示例:
- 通過Power BI報表/儀錶板使用的用戶。
- Lakehouse、Data Warehouse 和 KQL Database 都可以為 Power BI 提供服務。
- Lakehouse 和 Data Warehouse 都可以為具有相同直接湖模式語義模型功能的 Power BI 提供服務。(此處未詳細討論直接湖模式。或者通過 Lakehouse 的 SQL Analytics 端點或數據倉庫端點使用導入或 DirectQuery 模式。
- KQL 資料庫只能在啟用預覽功能「一個邏輯副本」時為具有直接湖模式的 Power BI 提供服務。稍後會詳細介紹。
- 使用即席 T-SQL 進行分析/探索的商業用戶
- Lakehouse、Data Warehouse 和 KQL Database 都提供 SQL 讀取功能。其他因素將決定哪種解決方案是最好的。
- 允許用戶直接在檔上使用 Spark,包括非結構化、半結構化和結構化數據以及所有文件類型(而不僅僅是 Delta表或 Delta parquet)。這可以適用於企業用戶、數據科學家等。
- Lakehouse 是正確的用例,因為可以存儲任何檔格式,並且 Spark 可用於與這些文件進行交互。數據倉庫允許Spark唯讀取表,這可能就足夠了,但通常不會將數據倉庫用於此方案。
- KQL 資料庫能夠使用 Spark 功能與表進行交互以進行讀取和寫入,但它將取決於其他因素,例如用例、ETL/ELT 或應用程式的需求、數據大小等,以確定是否應在湖倉一體上使用 KQL。
- 混合使用:來自執行轉換工作/數據建模的數據工程團隊的 PySpark 技能,以及使用只讀 T-SQL 查詢的企業用戶/開發人員,無論是直接對 Fabric 中的其他湖倉一體/倉庫進行臨時查詢,還是在 Power BI 中。
- Lakehouse 最適合這種情況。由於企業用戶使用只讀 T-SQL,因此他們可以使用湖倉一體上的 SQL Analytics 端點進行使用。數據工程團隊可以繼續在Spark中處理數據。
- 除非有其他要求/需求會強制使用數據倉庫,例如將倉庫端點用於第三方報告工具或分析查詢,或者需要僅在 Data Warehouse 中可用的功能,否則無需使用 Data Warehouse
- 例如,通過 SQL 的多表事務或 DML/DDL 功能
- 從技術上講,在此方案中,可以將 KQL 資料庫用於即時分析解決方案,因為在執行轉換時,可以通過 KQL/SQL 查詢或在 Power BI 中提供/使用數據。並且可以在數據倉庫、湖倉一體和其他 KQL 資料庫之間交叉查詢(通過啟用了“一個邏輯副本”的快捷方式) KQL 資料庫滿足此方案的要求,但是我會先從湖倉一體開始,然後根據解決方案的其他要求確定。在後面的部分我們會對此進行更多介紹。
- 例如,需要具有高性能和低延遲(不是“近即時”)的即時分析或時間序列和地理空間存儲/查詢支援。
每個資料庫、數據倉庫、Lakehouse、KQL、SQL Server、Cosmos DB 等都針對不同的讀/寫大小和工作負載進行了優化。因此,瞭解這些優化是確定哪種解決方案最適合滿足需求的關鍵。
應用程式或 ETL/ELT 的要求
對於不同的應用程式和 ETL/ELT,可能存在需要 Lakehouse、數據倉庫或即時分析/KQL 資料庫的特定功能的解決方案需求。同樣,每個解決方案的細微差別都不可能涵蓋所有方案,但我將介紹應用程式或 ETL/ELT 工作負載的 4 個常見要求。
ACID交易合規性
ACID 代表:
- 原子性(Atomicity)
- 交易中的每個語句都被視為一個單元。要麼執行整個事務,要麼不執行任何事務。
- 例如:銀行轉帳從您的帳戶中扣除資金並將其轉入另一個帳戶。如果沒有原子性,您可以從您的帳戶中扣除資金,而不會到達另一個帳戶。
- 交易中的每個語句都被視為一個單元。要麼執行整個事務,要麼不執行任何事務。
- 一致性(Consistency)
- 事務一致性。要求在事務中所做的更改與任何約束一致。防止任何這些錯誤或損壞進入您的數據。
- 例如:您嘗試從 ATM 中提取的錢比您帳戶中的錢多。交易失敗,因為它阻止透支,違反了約束。
- 事務一致性。要求在事務中所做的更改與任何約束一致。防止任何這些錯誤或損壞進入您的數據。
- 隔離性(Isolation)
- 所有事務都是隔離運行的,不會相互干擾。如果有多個事務對同一源應用更改,則它們將逐個發生。
- 例如:您的銀行帳戶中有 1,000 美元。您同時發送 2 次提款,每次 500 美元。如果這些同時發生,那麼您的結餘將為 500 美元。但是在隔離的情況下,結餘將為0美元,因為每筆交易都會影響另一筆交易。
- 所有事務都是隔離運行的,不會相互干擾。如果有多個事務對同一源應用更改,則它們將逐個發生。
- 耐久性(Durability)
- 確保對數據所做的更改保持不變。無論是寫入資料庫、保存檔等,只是在崩潰或系統故障時這些更改都是可用的。
為什麼ACID很重要?
- 符合 ACID 標準,絕不允許數據處於不一致狀態,從而實現最佳的數據完整性和可靠性。
Lakehouse 和 Data Warehouse 中的 ACID 合規性是什麼樣子的?
- Lakehouse ACID 合規性
- ACID 事務功能僅適用於 Delta 格式的表。
- 這意味著您必須利用託管Delta表才能具有 ACID 功能。
- Delta表使用 ACID 事務的基於文件的事務日誌擴展 parquet 檔。
- 可以使用 Spark 或 SQL 引擎對Delta表進行交互/獲得 ACID 支援。
- 非Delta表,也就是所有其他檔,在 Lakehouse 中將沒有 ACID 支援。
- 數據倉庫 ACID 合規性
- 數據倉庫中所有表都完全支援 ACID 事務。
- 所有表都是以 delta parquet 檔形式存儲在 OneLake 中的Delta表,其中包含基於文件的事務日誌。
- KQL 資料庫 ACID 合規性
- KQL 資料庫不支援 ACID 事務。
- KQL 資料庫是支持最終一致性的分散式系統,不支援事務。
- 可以使用“更新策略”將引入更新應用於多個表,但這不是ACID,因為這存在限制,並且它們不能用作支援ACID合規性的事務。
- KQL 資料庫是支持最終一致性的分散式系統,不支援事務。
- KQL 資料庫不支援 ACID 事務。
多表事務(Multi-table Transactions)
多表事務是一種將對多個表的更改分組到單個事務中的方法。這允許您控制讀取和寫入查詢的提交或回滾,並使用事務修改存儲在表中的數據以將更改組合在一起。
例如:您更改了影響三個表 (dbo.ItemStock、dbo.PurchaseOrderHistory,dbo。OrderShippingInfo)。您可以對取消訂單的交易進行分組,以便更改將應用於所有 3 個表或根本不應用。因此,當用戶查詢任何表時,他們將看到所有表的一致更改,而不是矛盾/不正確的數據。
多表事務僅在數據倉庫中受支援。
Lakehouse 目前不支援此功能。
KQL 資料庫不支援事務,它是一個支持最終一致性的分散式系統。KQL 資料庫可以通過「更新策略」實現類似於多表事務的更新行為,但這不符合 ACID 標準,也無法保證執行順序/持久性。
動態數據遮罩(Dynamic Data Masking)
動態數據遮罩通過將敏感數據遮罩給非特權使用者來限制敏感數據洩露。它使管理員能夠指定要顯示的敏感數據量,從而有助於防止未經授權查看敏感數據,同時將對應用程式層的影響降至最低。
- 通常對企業用戶遮罩的一些敏感字段是 SSN、電子郵件、帳號、PHI 等。
Lakehouse 數據遮罩:
- 僅通過 Lakehouse 的 SQL 分析端點支援。除 SQL(例如 Spark)以外的檔或引擎將無法使用動態數據遮罩。
- 還可以應用物件和行級別安全性(以及 DDM),但只能通過 SQL Analytics 端點。
- Spark 引擎將無法使用物件和行級別安全性。
- 將來可能會通過OneLake Security改變這種情況。可以在此處查看有關公共路線圖的更多資訊。Microsoft Fabric 中 OneLake 的新增功能和計劃內容 – Microsoft Fabric |Microsoft 學習
數據倉庫數據遮罩:
- 完全支援。
- 除了動態數據遮罩外,數據倉庫還支援 SQL 粒度許可權、列和行級別安全性以及審核日誌。
KQL 資料庫數據遮罩:
- 無。
- 您可以對表應用行級別安全性或受限視圖訪問策略,也可以嘗試創建僅公開選定列的視圖或函數,但不支援遮罩或加密敏感數據。
即時分析
即時分析在收集數據后能夠立即處理、查看、分析和測量數據的一般說明。這意味著數據必須以極低的延遲(例如在幾秒鐘內)可供使用。該解決方案必須能夠處理大量數據,同時提供幾秒鐘的收集延遲。您要考慮的大小將以 PB 或更高為單位,數據格式差異很大。即時分析的一些一般用例涉及安全審計日誌、庫存數據、從生產車間資產到送貨卡車的供應鏈資訊以及任何行業的流式智慧設備資訊。
數據倉庫:
- 數據倉庫不是即時分析的理想解決方案。
- 數據大小、格式和延遲要求並不能使數據倉庫成為即時分析解決方案的選項。
- 但是,您可以將數據從即時分析解決方案引入數據倉庫以進行進一步分析,也可以與現有數據相結合以獲得更多價值。
湖倉一體:
- Lakehouse 可能是即時分析的一個選項,但如果可能的話,這將取決於解決方案的要求。Lakehouse可能是一個選擇,但它不是首選。
- 如果您每秒有數百萬筆交易,而每筆交易只有 100-500 行數據,那麼 Lakehouse 可能能夠滿足即時分析解決方案的需求。因為這符合 Lakehouse 解決方案的潛在性能/延遲預期。但是,如果每秒數百萬個事務每個事務有數十萬或數百萬行,那麼 Lakehouse 將無法處理這個問題,並且不是一個可能的選擇。
- 這將取決於數據的併發性和大小,以確定湖倉一體是否能夠實現低延遲和高性能要求。
KQL 資料庫:
- KQL 資料庫是即時分析解決方案的最佳選擇。
- KQL 資料庫針對超大型寫入和高併發性進行了優化。每秒數百萬個事務,每個事務中有數十萬行的示例將能夠使用 KQL 資料庫以高性能方式進行處理。
- 通過對 KQL 資料庫中的表/資料進行自動索引和分區,以及對所有數據格式的支援,這是處理任何即時分析解決方案的最佳解決方案。
每個資料庫、數據倉庫、Lakehouse、KQL、SQL Server、Cosmos DB 等都針對不同的讀/寫大小和工作負載進行了優化。因此,瞭解這些優化是確定哪種解決方案最適合滿足需求的關鍵。
您的應用程式或 ETL/ELT 的要求摘要
這些只是分析解決方案中常見需求的 4 個示例,這些需求將決定使用哪個元件:Lakehouse、Data Warehouse 或 KQL Database。
對於 ACID 相容性,您需要查看解決方案的要求/其他因素,因為在數據倉庫和 Lakehouse 中使用 ACID 功能;需要創建一個Delta表(Lakehouse 和 Data Warehouse 中的所有表都是Delta表)。這意味著可能需要將文件轉換為Delta表,或者直接載入到兩個元件的Delta表中。您將無法使用 KQL 資料庫。因此,選擇將取決於用例的其他因素,例如技能集、其他要求和消耗。
對於多表事務,需要使用湖倉一體上的數據倉庫和 KQL 資料庫來執行這些事務。瞭解這一點可以在為使用者設計解決方案/功能時為您節省大量麻煩和時間。
對於動態數據遮罩,可以使用數據倉庫或 Lakehouse 和 KQL 資料庫來實現此功能。如果對 Lakehouse 使用 SQL 端點,如果您需要檔具有動態數據遮罩或其他引擎(如 Spark),那麼您當然可以嘗試設計您的 Lakehouse 以刪除敏感列並向業務使用者公開不同版本的數據,但是根據規模的不同,這很快就會變得難以管理。數據倉庫為業務使用者提供了一站式服務,並通過動態數據遮罩保護敏感資訊,而無需擔心檔或其他引擎的使用。
對於即時分析,需要使用 KQL 資料庫。根據確切的要求,您也許可以使用 Lakehouse,但 KQL 資料庫是針對此確切方案進行優化/設計的。與往常一樣,您當然可以嘗試在 Lakehouse 中設計解決方案,但 KQL 資料庫對於此方案的性能更高,並且具有許多現成的優化。Data Warehouse 不是即時分析解決方案的好選擇。
開發人員的技能組合
用例決策的最後一個主要類別是開發人員的技能組合。這包括公民開發人員、專業開發人員、數據工程師、數據科學家等。當我為客戶提供架構決策建議時,一個重要的資訊是瞭解處理數據的個人的技能。對於團隊來說,性能和成本的最佳服務/設計可能不是最佳解決方案,因為沒有人知道如何開發它。
- 這個概念的一個荒謬的例子是,如果您試圖讓您的團隊單獨駕駛一輛車從 A 點到 B 點。您決定到達那裡的最快方法是僅為您的團隊提供手動變速器車輛(變速桿),因為它們比自動變速器車輛更快。如果您知道如何駕駛變速桿,那麼您很快就會遇到問題。但是,如果您的整個團隊都不知道如何駕駛變速桿,那麼他們將需要更長的時間/在使用手動變速器時遇到問題。客觀地說,提供自動變速器而不是手動變速器可能不是最佳選擇,但它可能是您團隊的最佳選擇。
Lakehouse、Data Warehouse 和 KQL 資料庫所使用的技能集和開發人員類型的高階細分。
- Lakehouse
- 具有 Spark 知識和偏好的開發人員/使用者。直接使用 ETL/ELT 或其他工作負載的檔和/或Delta表。這包括使用 Spark 筆記本和 Spark 作業定義。
- 通常是數據工程師、數據科學家和專業開發人員
- 僅具有 T-SQL 知識的開發人員/使用者,只能讀取為他們特選的數據(通過 SQL Analytics 端點在Delta表中)以供使用或分析。
- 通常是公民開發人員和專業開發人員
- 具有 Spark 知識和偏好的開發人員/使用者。直接使用 ETL/ELT 或其他工作負載的檔和/或Delta表。這包括使用 Spark 筆記本和 Spark 作業定義。
- 數據倉庫
- 在構建 ETL/ELT 時具有 T-SQL 知識和偏好的開發人員/使用者。處理存儲過程、函數和 DBA 任務的數據倉庫專家。
- 通常是數據倉庫工程師和 SQL 開發人員
- 僅具有 T-SQL 知識的開發人員/使用者,只能讀取為他們策劃的數據以供使用或分析。
- 通常是公民開發人員和專業開發人員
- 在構建 ETL/ELT 時具有 T-SQL 知識和偏好的開發人員/使用者。處理存儲過程、函數和 DBA 任務的數據倉庫專家。
- KQL 資料庫
- 具有 KQL 知識和偏好的開發人員/使用者。您將能夠使用 Spark 或 T-SQL 語句與數據進行交互(讀/寫),但 KQL 是目前與數據互動的最佳選擇。
- 開發人員/用戶可以通過Power BI 連接器或不同的檢視、查詢或函數作為源使用。
- 具有 KQL 知識和偏好的開發人員/使用者。您將能夠使用 Spark 或 T-SQL 語句與數據進行交互(讀/寫),但 KQL 是目前與數據互動的最佳選擇。
用例總結
在查看了一些常規用例以及您可能具有的不同要求后,應該更清楚何時使用 Lakehouse、數據倉庫和 KQL 資料庫。通常,這些決定很複雜,需要考慮很多因素。首先;分析數據的使用/使用方式、應用程式或 ETL/ELT 的要求以及開發人員/使用者的技能組合可以更快地做出設計/架構決策。如果沒有,那麼至少您會找出其他需要詢問的問題。
數據湖倉一體、數據倉庫和即時分析/KQL 資料庫的解決方案架構/設計
瞭解 Data Lakehouse、Data Warehouse 和 KQL 資料庫之間的功能、特性支援、用例和差異將有助於您建構不同類型的解決方案構建體系架構。我們將結合到目前為止所學到的所有內容,並將其應用於不同工作負載/方案的體系結構。
這些示例並非旨在作為參考體系結構或跨所有方案的特定最佳實踐的建議,因為我們僅介紹了一些需要考慮的複雜性。
目標是演示僅使用 Lakehouse、僅使用數據倉庫、僅使用即時分析/KQL 資料庫、一起使用 Lakehouse 和數據倉庫以及同時使用即時分析/KQL 資料庫和 Lakehouse 或數據倉庫的體系結構,以便根據您的條件更好地瞭解不同的設計模式。
解決方案體系結構/設計將分為以下幾類:
- Medallion 架構概念審查
- Lakehouse 示例架構
- 數據倉庫示例體系結構
- Lakehouse 和 Data Warehouse 組合架構
- 即時分析/KQL 資料庫體系結構
獎章建築概念審查(Medallion Architecture Concept Review)
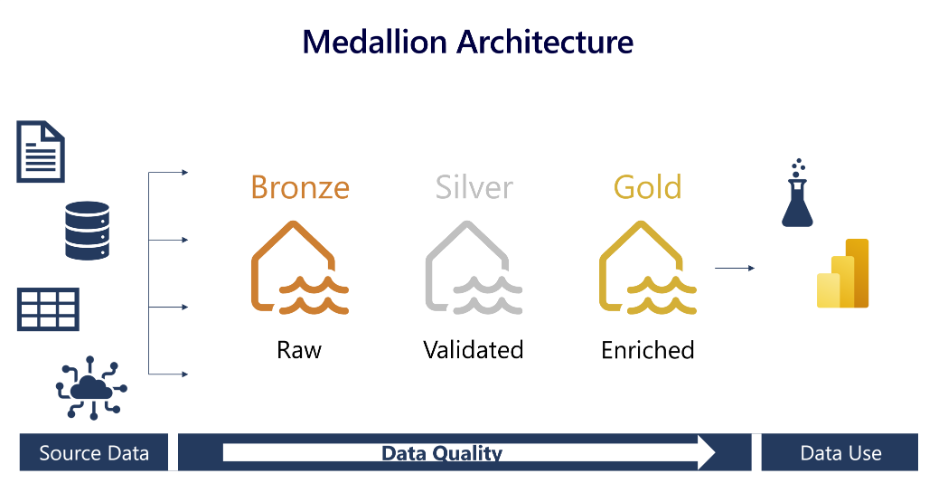
Medallion架構並非 Fabric 獨有,它已成為雲中湖倉一體/數據倉庫架構的最佳實踐/非常常見。它仍然是 Fabric 的最佳實踐。因此,在深入研究使用它的特定架構之前,我們回顧一下Medallion架構的基礎知識非常重要。Medallion體系結構是 Fabric 中推薦的方法。
Medallion架構描述了一系列數據層,這些數據層表示存儲在湖倉一體中的數據品質。獎章架構由三個不同的層或區域組成:青銅(原始)、銀(已驗證)和黃金(豐富)。每一層都表示存儲在湖倉一體中的數據質量,級別越高表示品質越高。
區域的名稱,例如銀區域的「已驗證」 ,可能因來源和設計而異,但概念是相同的。
青銅
原始區域,第一層以原始格式存儲源數據。
通常在此層幾乎沒有使用者訪問許可權。
銀
豐富區,經過清理和標準化的原始數據。數據現在由行和列構成,並且可以與整個企業中的其他源集成。
白銀級別的轉換應側重於數據品質和一致性,而不是數據建模。
金
策劃區,最後一層來自銀層。這些數據經過優化,「業務就緒」 ,並滿足分析/ 業務需求。
根據需求這可以是湖倉一體或數據倉庫,下面將詳細介紹此設計。
您可以為不同的使用者或域設置多個黃金層,並進行特定的優化/設計。例如,您可能為財務和銷售設置了單獨的黃金層,這些金層利用 STAR 模式並針對分析/報告進行了優化。此外,您可能還為數據科學家準備了一個針對機器學習進行優化的黃金層。
Lakehouse 示例架構
這是一個使用Medallion架構的湖倉一體架構示例。以下是有關圖表不同部分的註釋。
使用此體系結構模式的一般決策點:
- 開發人員團隊的技能集主要是Spark。
- 不需要數據倉庫的其他功能,如多表事務和動態數據遮罩。
- 消費者無需將數據倉庫端點用於某些第三方報告工具所需的功能。
- 用戶/開發人員不需要 T-SQL DDL/DML 功能。
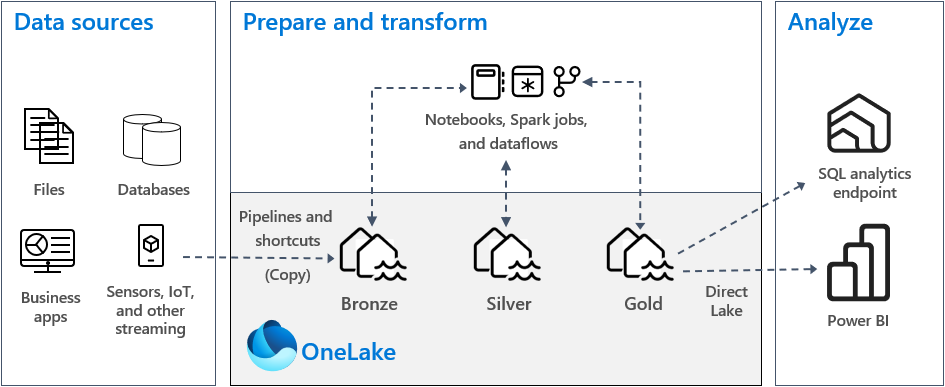
資料來源:
- 可以是任何來源,從檔到流數據以及介於兩者之間的所有內容。
- 此數據可以來自本地位置、Azure 位置、其他雲供應商位置、快捷方式或 Fabric 本身內部。
準備和轉換:
引入方法:
- 我們沒有詳細介紹引入方法,但您可以選擇各種無代碼、低代碼或代碼選項。
- 目標是將數據放在 Bronze Lakehouse(原始層)中。
- 結構管道
- 200+ 本機連接器是 Microsoft 結構管道的一部分。
- 數據流
- 快捷方式
- 數據源包括:OneLake、Azure Data Lake Store Gen2 (ADLS Gen2)、Amazon S3 或 Dataverse。
- Spark 筆記本/作業
- 包括流數據和檔/資料庫連接。
- 結構管道
所有區域轉換/資料提升方法:
- 將取決於無代碼、低代碼或代碼選項的技能集。
- Spark
- 可以是筆記本或 Spark 作業定義
- 複雜方案和高代碼選項的首選方法。對於複雜的轉換方案,性能將達到最佳。
- 數據流
- 低代碼選項,可執行簡單的轉換,最適合小型數據集。
- Microsoft 結構管道的業務流程
- Spark
青銅Lakehouse:
- 盡可能將數據保留為原始格式。如果無法做到這一點,請使用 Parquet 或 Delta Parquet 作為轉化目標。
- 原因是性能。
- 將數據載入到 Lakehouse 中後,可以利用 OneLake/Azure 位置的更好性能以及 Fabric 中提供的優化和可縮放的無伺服器計算來執行任何必要的轉換或轉換。與在中途進行轉換相比,您可能無法利用優化的可擴展計算/低延遲。
- 如果源數據與快捷方式相容,則在青銅區域創建一個快捷方式,而不是複製數據。
銀Lakehouse:
- 如果可以建議使用 Delta 表。
- Fabric 中內置了專門針對 Delta 表的額外功能和性能增強。
- 例如,對 parquet 檔案格式的 V-Order 寫入時間優化。這允許 Fabric 中可用的不同計算引擎進行極快的讀取。
- Ex. SQL引擎、Power BI 引擎、Spark 引擎
- 例如,對 parquet 檔案格式的 V-Order 寫入時間優化。這允許 Fabric 中可用的不同計算引擎進行極快的讀取。
- 在這個區域,您將開始豐富您的數據。具體情況將取決於需要做什麼。無論是將其他數據源組合在一起、轉換現有數據、數據清理等,白銀區域都是執行這些操作的區域。
黃金Lakehouse:
- 使用Delta Tables的建議與Silver Lakehouse相同。
- 這個區域將是「商業就緒」的湖倉一體。這意味著您的數據位於 STAR 架構數據模型中,數據已規範化,並且已應用業務邏輯,因此數據已準備好供使用。
- 建議將每個 Lakehouse分隔成自己的結構工作區。與將所有湖倉一體放在一個工作區中相比,這允許在每個區域級別進行更好的控制和治理。
分析:
使用者將透過 2 種方法使用和分析資料:
Gold Lakehouse 的 SQL Analytics 端點
使用者/團隊可以將數據提取到不同的報告工具中,甚至可以在湖倉一體和數據倉庫之間進行跨資料庫查詢,以滿足不同的報告需求。
這也是探索或臨時分析的方法。無論是業務用戶還是 SQL 分析師/開發人員,SQL Analytics 端點都能夠從 Gold Lakehouse 獲得完整的唯讀 SQL 體驗。
通過 SQL Analytics 端點,特權使用者可以應用物件級別和行級別安全性來保護敏感數據。您可以創建視圖和函數來自定義和控制最終用戶的體驗,就像許多使用者習慣的傳統 SQL 環境一樣。
Power BI
使用者/團隊將通過報表、數據集、儀錶板、應用等通過Power BI使用數據,這些都來 Gold Lakehouse。
直接湖模式是一種新的語義模型功能,用於直接從數據湖載入 parquet 格式的檔,而無需查詢湖倉一體端點或在 Power BI 模型中導入/複製數據。
- 了解 Power BI 和 Microsoft 結構中的直接湖 – Power BI |Microsoft 學習
- 您仍然可以根據需求從 Gold Lakehouse 使用導入模式和 DirectQuery。
數據倉庫示例體系結構
下面是數據倉庫體系結構的範例,以下是有關圖表不同部分的註釋。
使用此體系結構模式的一般決策點:
- 開發人員團隊技能集主要是 T-SQL/數據倉庫技能集。
- 使用存儲過程轉換數據
- 需要支援多表事務等功能,而這些功能僅受數據倉庫支援。
- 例如事務性工作負載(OLTP 與 OLAP)。
- 這並不意味著事務性工作負載只能使用 Data Warehouse。他們可以根據應用程式或 ETL/ELT 的要求使用 Lakehouse。
- 例如事務性工作負載(OLTP 與 OLAP)。
- 使用需要數據倉庫端點才能實現第三方報告工具或流程所需的 Lakehouse SQL 端點中不可用的功能。
- 用戶/開發人員需要 T-SQL DDL/DML 功能。
- 工作負載要求用戶能夠修改數據,即使數據已規範化或轉換。
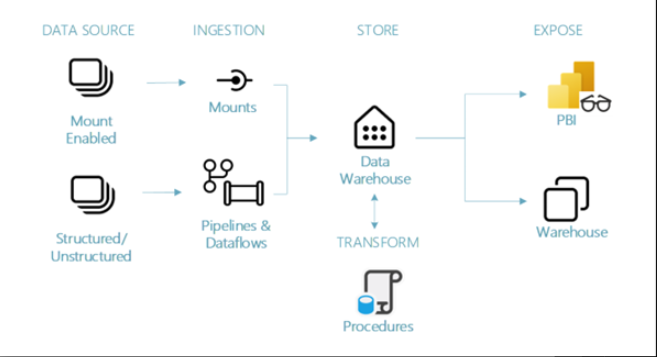
資料來源:
- “Mount Enabled”指的是快捷方式。如果您能夠使用快捷方式,建議您使用它。快捷方式允許您在不物理複製或移動資料的情況下使用數據。
- 數據源包括:OneLake、Azure Data Lake Store Gen2 (ADLS Gen2)、Amazon S3 或 Dataverse。
- 結構化/非結構化
- 包括來自其他 Azure 數據服務、其他雲平台、本地源等的數據。
引入:
- “Mounts”指的是快捷方式。它列在引入下,但快捷方式允許您連接數據,而無需複製或移動數據。您可以從快捷方式在倉庫中創建表,這些表將為您從快捷方式引入的數據進行數據移動。
- 管道和數據流
- Fabric Pipelines 提供了使用 200+ 本機連接器將數據攝取到倉庫中的能力。
- 如果需要您可以使用管道中的複製活動來存儲數據,或者使用數據流進行中動態轉換。
- 熟悉 Azure 數據工廠的使用者會在 Fabric Pipelines 中找到類似的功能和概念。
商店:
倉庫設計:
儘管圖中未顯示,但仍建議在數據倉庫設計中明確分隔數據區域。就像 Medallion架構一樣,但使用數據倉庫而不是湖倉一體。數據倉庫通常具有與獎 Medallion體系結構相同的概念,具有登陸區域、暫存區域和生產區域的一些概念,這些概念提供與 Medallion體系結構相同的優勢。
建議在 Fabric 數據倉庫中也實現此概念。為此有 2 種選擇,具體取決於可容忍的行政監督量。
- 將青銅層、銀層和金層分隔到各自工作區中的單獨數據倉庫中。
- 您仍然可以交叉查詢到不同的倉庫,以方便數據移動/使用數據,但這提供了自然的安全性和治理邊界。
- 單個倉庫,具有針對不同區域的架構/表實施。
- 這可能會導致大量開銷和蔓延,但適用於物件/安全要求不多的小型數據倉庫。
- 每個區域都將在架構中描述,並通過架構在單個倉庫中提供青銅、白銀和黃金。
- 例如 bronze.Patient、silver.Patient、gold.Patient
- 您需要強制實施不同的物件級安全性,以防止用戶發現/處理他們不應該發現的數據,例如敏感數據、原始數據等。
- SQL 粒度許可權、物件/架構安全性、行/列級安全性和動態數據遮罩都可以使用
- 在規模化管理時可能會有很多管理工作。
資料轉換:
- 建議使用 SQL 儲存過程。
- 這是通過倉庫中的完整 DDL/DML 功能實現的。
- 現在可以通過ADF等結構管道進行ETL(使用SQL儲存過程進行轉換)。
暴露:
倉庫:
- 使用者/團隊可以將數據提取到不同的報告工具中,甚至可以在湖倉一體和數據倉庫之間進行跨資料庫查詢,以滿足不同的報告需求。
- 這也是用於探索、臨時分析或使用者執行 DDL/DML 語句的方法。
- 無論是業務用戶還是 SQL 分析師/開發人員。使用 SQL 粒度許可權,您可以定義每個使用者/安全組/使用者具有的訪問/許可權級別。
- 您可以通過動態數據掩碼應用物件級別、行級別和列級別安全性,以防止暴露敏感數據。
- 您可以創建視圖和函數來自定義和控制最終用戶的體驗和訪問,就像許多使用者習慣的傳統 SQL 環境一樣。
- 第三方報告工具或其他需要僅通過 Data Warehouse 端點才能獲得功能的流程。
Power BI:
- 使用者/團隊將通過報表、數據集、儀錶板、應用等通過Power BI使用數據,這些來自黃金倉庫或表。
- 直接湖模式是一種新的語義模型功能,用於直接從數據湖載入 parquet 格式的檔,而無需查詢倉庫端點或在 Power BI 模型中導入/複製數據。
- 了解 Power BI 和 Microsoft 結構中的直接湖 – Power BI |Microsoft 學習
- 如果需要,您仍然可以從黃金倉庫或表中使用導入模式和 DirectQuery。
數據倉庫和湖倉一體示例架構
下面是 Data Warehouse 和 Lakehouse 組合架構的範例,以下是有關圖表不同部分的註釋。
使用此體系結構模式的一般決策點:
- 開發人員團隊的技能集主要是Spark。
- 使用 Spark 筆記本轉換數據
- 需要通過 T-SQL 支援最終使用者 DDL/DML 功能等功能,這僅受數據倉庫支援。
- 工作負載要求用戶能夠修改數據,即使數據已規範化或轉換。
- 使用需要某些第三方報告工具或處理的數據倉庫端點中的功能。
此架構圖與 Lakehouse Medallion架構圖相同,但有 2 個不同之處。
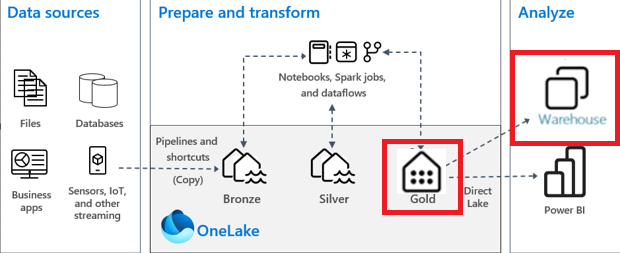
此體系結構與僅 Lakehouse 體系結構之間的差異:
- Gold Lakehouse 被 Gold Data Warehouse 取代。
- 通過 Lakehouse 的 SQL Analytics 端點的消耗量將替換為數據倉庫端點。
為什麼要組合這些架構?
將 Lakehouse 和 Data Warehouse 合併到一個體系結構中可以為您提供兩全其美的效果(具體取決於您的要求)。
使用此體系結構,可以允許消耗層(通過 Power BI 或倉庫端點)充分利用數據倉庫,例如在黃金層為使用者/開發人員提供 DDL/DML 支援,併為其他報告工具/流程提供數據倉庫端點,而不必僅僅為了不同的使用方法而犧牲性能或複製數據。ETL/ELT 中的所有數據轉換都使用 Spark 執行,以實現代碼的最佳性能和靈活性,同時利用開發人員的主要技能集,同時仍能提供最佳的最終用戶體驗/功能。
即時分析/KQL 資料庫範例體系結構
下面是即時分析/KQL 資料庫體系結構的示例,以下是有關圖表不同部分的註釋。
使用此體系結構模式的一般決策點:
- 即時資料分析要求(延遲以秒為單位)
- 通常客戶會解釋對「即時」需求的需求,經過討論,要求是“近乎即時”。這意味著延遲要求不是以秒為單位,而是以小時或分鐘為單位。“近實時”有時被誤解為即時。這種區別很重要,因為即時分析指的是以秒為單位的延遲。根據其他要求,近實時解決方案可能不使用 KQL 資料庫。
- KQL 資料庫即使在非常大規模的情況下也能提供高性能、低延遲和高新鮮度。
- 需要有無限的擴展性。
- 這種無限縮放適用於查詢併發/大小、引入流/大小和存儲大小。
- 所有內容都會在 KQL 資料庫中自動編製索引和分區。
- 這種無限縮放適用於查詢併發/大小、引入流/大小和存儲大小。
- 複雜數據結構的即時數據轉換要求。
- 要求使用任何數據源和/或任何數據格式。
- 使用內置的時間序列資料庫和/或地理空間功能的要求。
- 可以通過 Power BI、Lakehouse 中的筆記本、數據管道/數據流或使用者查詢進行使用。
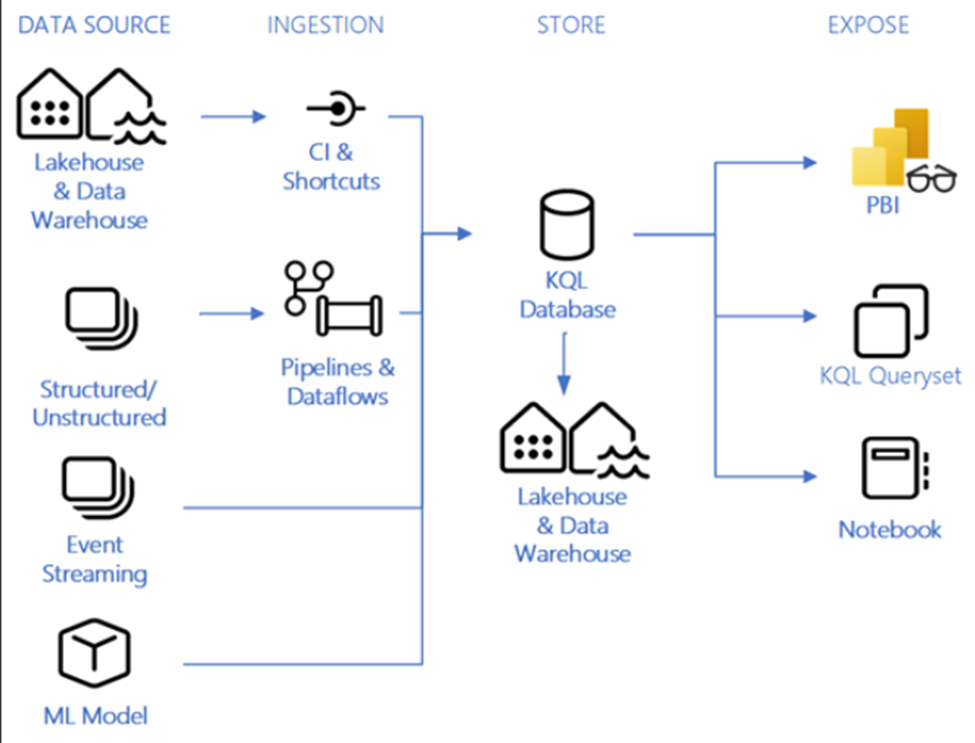
資料來源:
- 任何數據源和任何數據格式都可以在這裡使用。
- Lakehouse 和 Data Warehouses 可以具有跨資料庫查詢,也可以是 KQL 資料庫的源。
- 事件流式處理源(如事件中心、IoT 中心或其他開源生態系統(Kafka、Logstash、Open Telemetry 等)可以使用 KQL 資料庫作為其流式處理目標。
引入:
- 通過事件中心雲連接將數據流式傳輸到即時分析中 從 Azure 事件中心獲取數據 – Microsoft 構造 |Microsoft 學習
- Microsoft Fabric 中的事件流功能使您在 Fabric 平台中提供了一個集中的位置,可以捕獲、轉換即時事件並將其路由到具有無代碼體驗的各種目標。
- Fabric 事件流中的所有內容都側重於事件數據。捕獲、轉換和路由事件數據是事件流的基本功能。該功能具有可擴展的基礎結構,由 Fabric 平台代表您進行管理。
- 快捷方式,如果您能夠使用快捷方式,建議您使用它。快捷方式允許您在不物理複製或移動資料的情況下使用數據。
- 數據源包括:OneLake、Azure Data Lake Store Gen2 (ADLS Gen2)、Amazon S3 或 Dataverse。
- 管道和數據流
- Fabric Pipelines 提供了使用 200+ 本機連接器將數據攝取到倉庫中的能力。
- 如果需要,可以使用管道中的複製活動來登陸數據,或者使用數據流通過動態轉換來登陸數據。
- 熟悉 Azure 數據工廠的使用者會在 Fabric Pipelines 中找到類似的功能和概念。
- 駐留在 OneLake 中的數據
- 載入到即時分析中的數據將作為一個邏輯副本反映在 OneLake 中。 一個邏輯副本(預覽版) – Microsoft 結構 |Microsoft 學習
- OneLake的數據可以通過即時分析作為快捷方式進行查詢。
- OneLake 中的數據可以通過管道、查詢、數據流或在 Fabric UI 中手動載入到 Real-Time Analytics 中。
商店:
KQL 資料庫:
KQL 資料庫是即時分析的數據存儲,所有的好處和用例都在上面。Medallion體系結構不會在 KQL 資料庫中使用,因為這適用於原始遙測數據,建模/清理發生在飛行中或使用層。仍建議在 KQL 物件中具有某種組織或命名約定。
設計即時分析解決方案的一個重要概念是存檔。您需要制定一個存檔策略,以防止數據在不需要時增長/產生成本。為什麼要存檔數據?最有可能的是,即時分析解決方案中的數據只在很短的時間內有價值,而對於更多的歷史分析,您有不同的資產。每個解決方案都有不同的要求和業務需求,因此要保留的數據量可能會有所不同,但很少有真正要求將所有數據保留在即時分析解決方案中。
- 例如,在製造業中,瞭解生產車間機械的當前狀態對於儀錶板/分析至關重要。但是,30 天前特定時間甚至 3 天前的狀態與範圍無關或有用。在這裡,存檔數據將允許您刪除資料或將其移動到其他地方,以提供更深入的分析/趨勢分析、與倉庫數據相結合或您可能擁有的任何其他用途。這將有助於提高性能和成本。
在 Real-Time Analytics 中,您可以定義數據保留策略,並以不同的方式將數據匯出到不同的目標。
Lakehouse & Data Warehouse:
包含 Lakehouse 和 Data Warehouse 的原因是為了更深入地分析或進一步使用超出即時分析報告範圍的分析。這樣做的好處是,該解決方案為您提供即時分析,並保留要用於其他分析報告的數據的歷史保留。
一個邏輯副本(預覽版)允許您與 OneLake 中 KQL 資料庫中的數據進行交互,從而允許您處理數據,而無需為不同的計算引擎物理複製數據。提供湖倉一體或數據倉庫使用快捷方式連接到 KQL 中的數據的功能,而無需將其物理複製到湖倉一體。
現在,如果出於歷史保留或其他原因要將該數據載入到不同的文件或倉庫中,則需要物理移動/複製數據。在 KQL 中啟用一個邏輯副本時,可以通過管道、數據流、Spark 筆記本,甚至在 Lakehouse、Datawarehouse 和 KQL 資料庫之間跨資料庫查詢功能(允許創建快捷方式)來實現此目的。
如果使用 KQL 資料庫作為數據倉庫或湖倉一體的數據源,請查看上述體系結構,瞭解實現這些解決方案時的準則。
暴露:
Power BI:
使用者/團隊將通過報表、數據集、儀錶板、應用等通過Power BI使用數據,這些來自黃金倉庫或桌子。
當您啟用「一個邏輯副本」 時,您將能夠使用直接湖模式。
直接湖模式是一種新的語義模型功能,用於直接從數據湖載入 parquet 格式的檔案,而無需查詢倉庫端點或在 Power BI 模型中導入/複製數據。 了解 Power BI 和 Microsoft 結構中的直接湖 – Power BI |Microsoft 學習
否則,您將不得不使用導入模式或直接查詢模式。
KQL 查詢集:
KQL 查詢集是用於對 KQL 資料庫中的數據運行查詢、查看和自訂查詢結果的項。
使用 KQL 建立查詢、檢視、函數、控制命令、自定義結果和許多 SQL 函數。
KQL 查詢集中有一些選項卡,可用於連接/關聯不同的 KQL 資料庫,並將它們切換出來以在不同狀態下運行相同的查詢。
您可以與他人協作並保存查詢。
筆記本:
還可以通過 Spark/KQL 使用筆記本瀏覽數據。
這使您能夠直接從 KQL 資料庫通過筆記本引入、分析、在機器學習或任何進程中使用。
結論
在考慮在 Fabric 中創建新解決方案或遷移現有解決方案時,瞭解 Fabric 元件的功能和解決方案要求至關重要。通過檢查數據倉庫、Lakehouse 和 Real-Time Analytics/KQL 資料庫的不同用例、不同體系結構模式的示例,並深入瞭解每個數據倉庫、Lakehouse 和 Real-Time Analytics/KQL 資料庫的功能,當與使用者/工作負載要求的知識相結合時,應該會有更清晰的體系結構設計路徑。
文章來源:
什麼是OneLake?– Microsoft面料 |Microsoft 學習
什麼是湖倉一體?– Microsoft面料 |Microsoft 學習
什麼是 Microsoft Fabric 中的數據倉庫?– Microsoft面料 |Microsoft 學習
結構決策指南 – 選擇數據存儲 – Microsoft Fabric |Microsoft 學習
教程:將數據引入湖倉一體 – Microsoft Fabric |Microsoft 學習
構造決策指南 – 複製活動、數據流或Spark – Microsoft Fabric |Microsoft 學習
OneLake 快捷方式 – Microsoft Fabric |Microsoft 學習
在 Microsoft Fabric 中實現獎章湖倉一體體系結構 – Microsoft Fabric |Microsoft 學習
即時分析概述 – Microsoft Fabric |Microsoft 學習
即時分析和 Azure 數據資源管理器之間的差異 – Microsoft Fabric |Microsoft 學習
使用 Microsoft Fabric 中的 Synapse 即時分析感知、分析和生成見解 |Microsoft 結構博客 |Microsoft 結構
Fabric Change the Game:即時分析 |Microsoft 結構博客 |Microsoft 結構


